
More Skills, Worse Results? The Hidden Physics of Agent Skill Libraries
More Skills, Worse Results? The Hidden Physics of Agent Skill Libraries
We gave our agents hundreds of real-world skills and expected them to get smarter. Instead, they started picking the wrong tool — and the failures weren’t random. They followed precise, predictable patterns that look more like phase transitions in physics than software bugs.
3 million API calls. 11 leading LLMs. 989 real-world skills. What emerged was a set of empirical laws that govern how agentic skill ecosystems actually behave at scale — and they challenge a core assumption in agent design: that more tools means better performance.
Tested on: GPT-4o-mini · GPT-5-mini · GPT-5.4-mini · GPT-5.4 · Claude Sonnet 4.6 · Claude Opus 4.6 · Gemini 3.1 Pro · Gemini 3.1 Flash Lite · GLM-5 · Kimi K2.5 · Doubao Seed 2.0 Pro

Figure 1: Performance contour map over pipeline depth and skill library size . Clear safe zones and dead zones emerge — as and increase together, the system rapidly enters an unreliable regime.
Figure 1 is conceptual; the following figures test each piece of this map with empirical data.
Here’s the paradox: a library of 1,000 skills can route at near-perfect accuracy — if the skills are semantically well-separated. But pack just 30 similar skills into the same neighborhood, and accuracy collapses. The bottleneck isn’t how many tools you have. It’s how crowded the densest corner of your skill space is.
Every new skill adds capability, but it also adds competition. That competition follows rules we can now describe, predict, and engineer against.
The Logarithmic Wall: Why Routing Accuracy Has a Hard Ceiling
As you add more skills to the library, how does single-step routing accuracy change?
The answer is surprisingly clean. Every doubling of the skill library costs a fixed accuracy penalty. Across all 11 models and diverse real-world skill sets, this relationship holds with :
This isn’t random degradation — it’s a fundamental ceiling. A router operates under finite representational power, and every skill description competes for the same semantic resources. As the library grows, the salience of any single skill gets continuously diluted. Distinguishability itself is a finite resource.
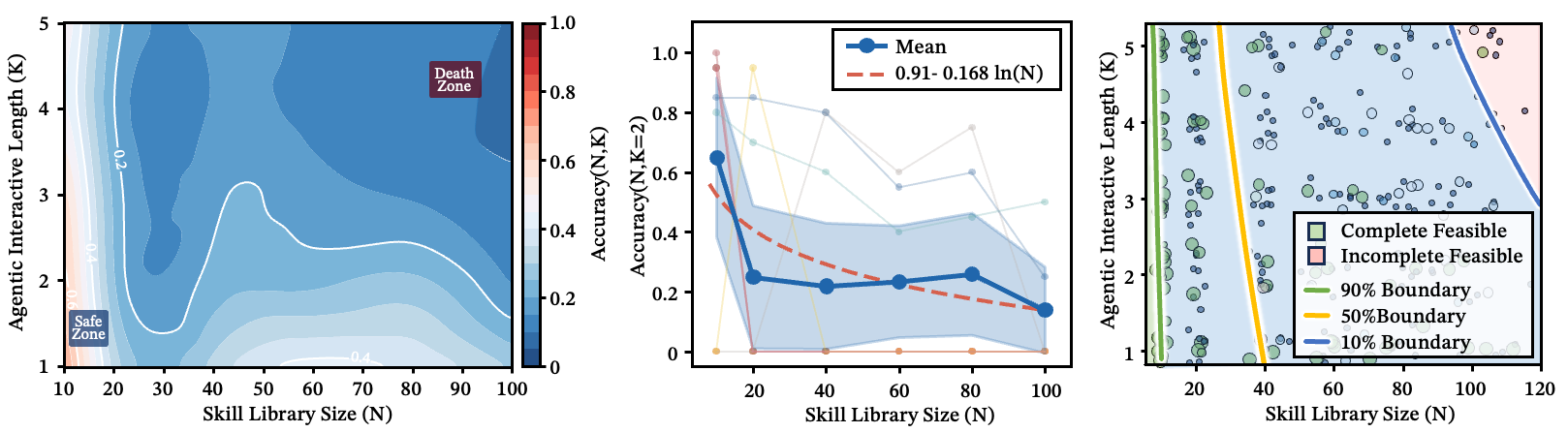
Figure 2: Aggregate fitted curves across 11 models. Different models have different decay slopes, but the logarithmic form is universal.
The compounding problem in multi-step pipelines
This gets much worse when agents chain multiple skills. Three steps at 85% accuracy each doesn’t give you 85% end-to-end — it gives you 61%:
At and , single-step accuracy around 85% yields only ~20% end-to-end success. A router that looks fine in isolation is already in an unstable regime for real pipelines. The empirical curve decays even more steeply than theory predicts, due to error cascades and context contamination.
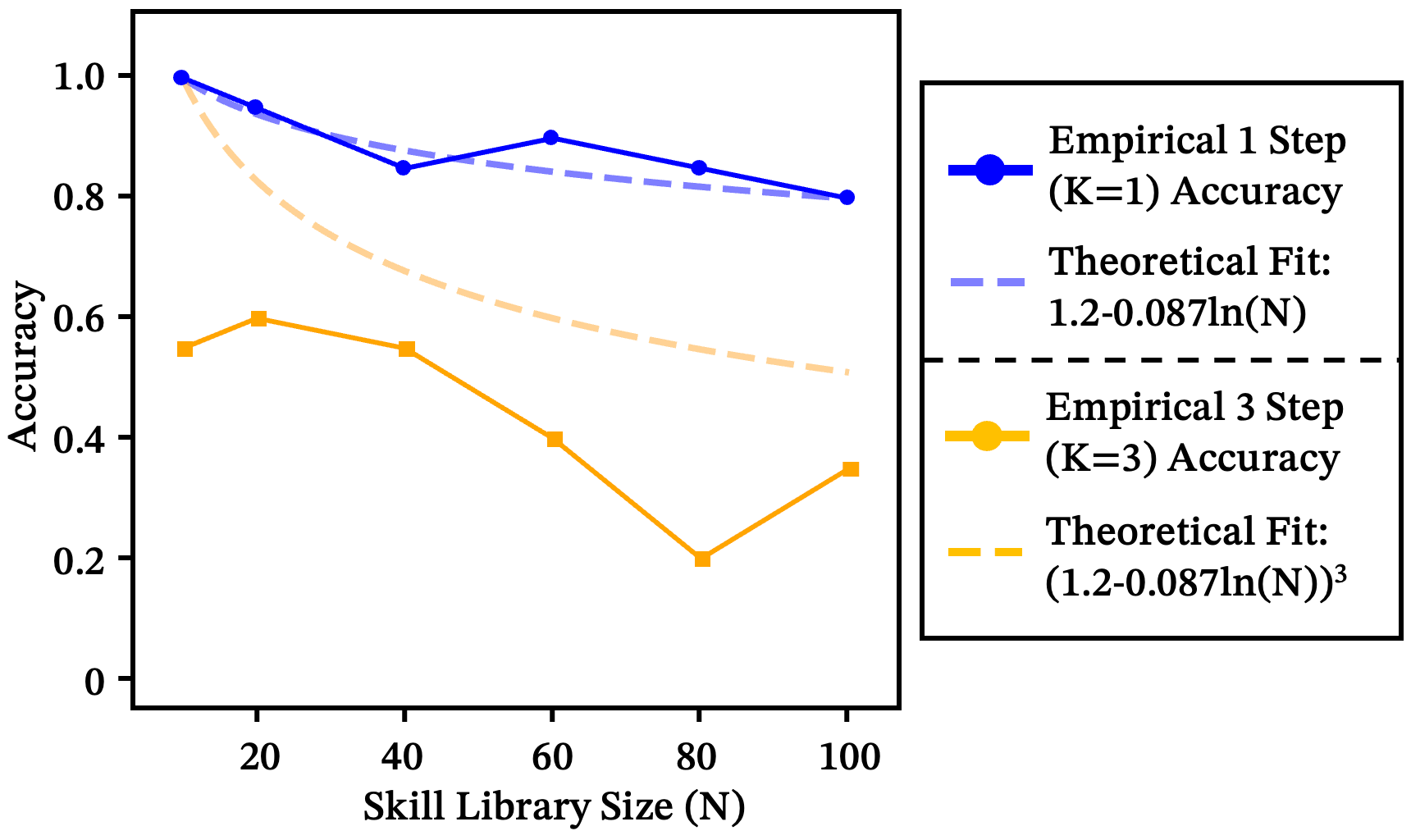
Figure 3: Theoretical (dashed) vs. empirical (solid) decay.
What makes a good skill description?
Length matters — up to a point. Longer descriptions improve routing performance, but the gains plateau around 280 tokens. Below ~236 characters, there’s a clear accuracy cliff.
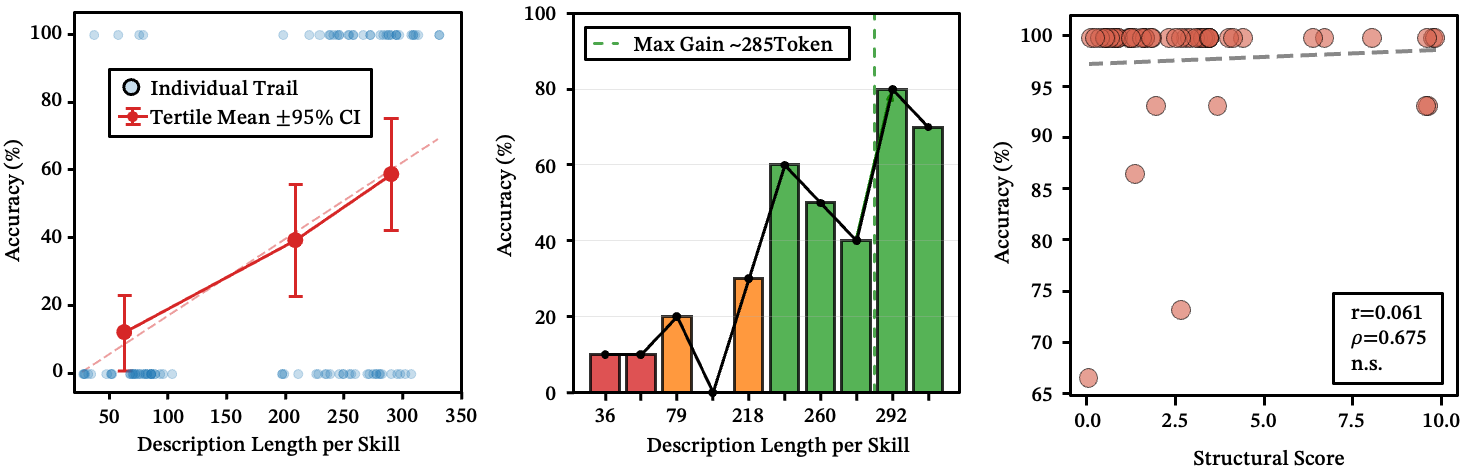
Figure 4: (a-b) Description length vs. routing accuracy. A clear split emerges at 236 characters. (c) Structural score vs. routing accuracy — no significant correlation.
Surface-level structure doesn’t help. Skills tend to be written in highly structured formats. We tested whether better formatting improves routing by scoring descriptions on structural quality. The correlation with accuracy? Not statistically significant. The router doesn’t care about your bullet points.
Systematic disambiguation is what actually works. If the logarithmic wall is the bad news, here’s the good news: skill description quality is the single largest lever available to system designers. The gap is enormous — at , well-crafted descriptions (L5) retain 72% accuracy while minimal labels (L1) fall to 11%. That’s a 61-point difference.
We define five quality levels:
- L1: Skill name only
- L2: Add a one-sentence functional summary
- L3: Add the target object and typical actions
- L4: Add applicable constraints and usage examples
- L5: Add boundary conditions and counterexamples (when the skill should not be called)
The jump from L4 to L5 is the most revealing. Both levels have similar token counts, yet L5 gains ~7% accuracy. The difference isn’t length — it’s the counterexample clause ("do not use this skill for X; use Y instead"). That’s exactly the information that breaks ambiguity between similar skills.
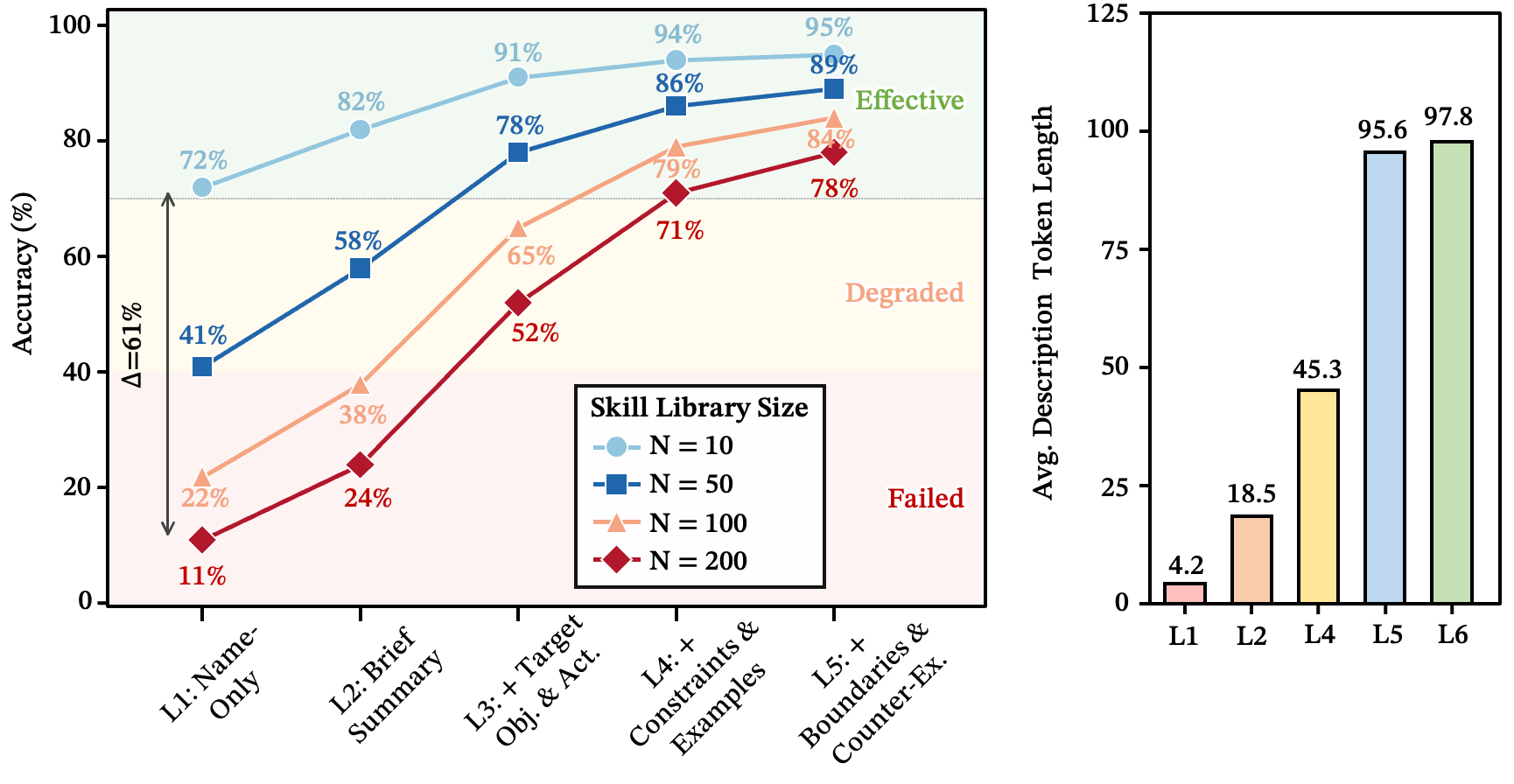
Figure 5: Top-1 routing accuracy across five description-quality levels at . The dashed line marks the 70% deployment threshold.
Good descriptions don’t just describe — they claim territory in semantic space. What matters isn’t how "clear" a description reads in isolation — it’s how much semantic territory it occupies relative to its competitors. We call this semantic radius, and it positively predicts routing accuracy across all 11 models.
See also: semantic radius vs. routing accuracy
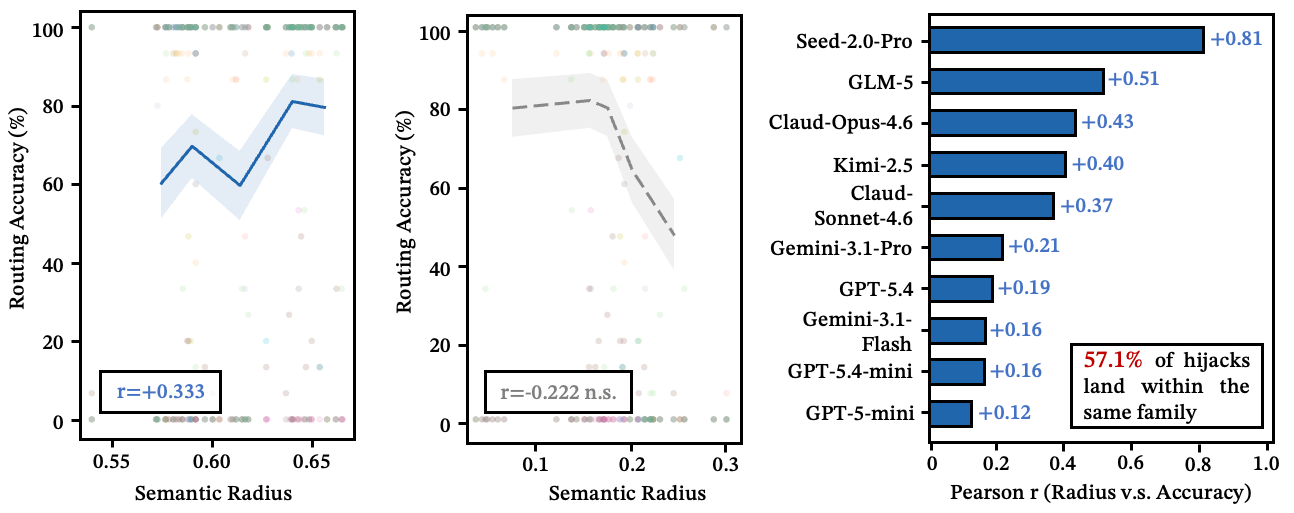
Figure 6: (Left) Larger semantic radius correlates with higher accuracy; (Center) intra-family clarity shows no significant effect; (Right) per-model correlation — all 11 models show positive correlation.
When Routing Fails, It Fails in Predictable Ways
So routing has a hard ceiling. But here's the thing — when it breaks, the errors aren't noise. They're structured.
94% of errors stay in the right neighborhood
Across 989 real-world skills, the vast majority of routing failures land within the target skill’s functional cluster. The model almost always finds the right domain — Git, testing, databases, file processing — but picks the wrong specific skill within that domain. It’s not global confusion; it’s local competition.
A task that needs git_rebase gets routed to git_merge. A task for run_pytest lands on run_unittest. The system reaches the right shelf but grabs the wrong book.
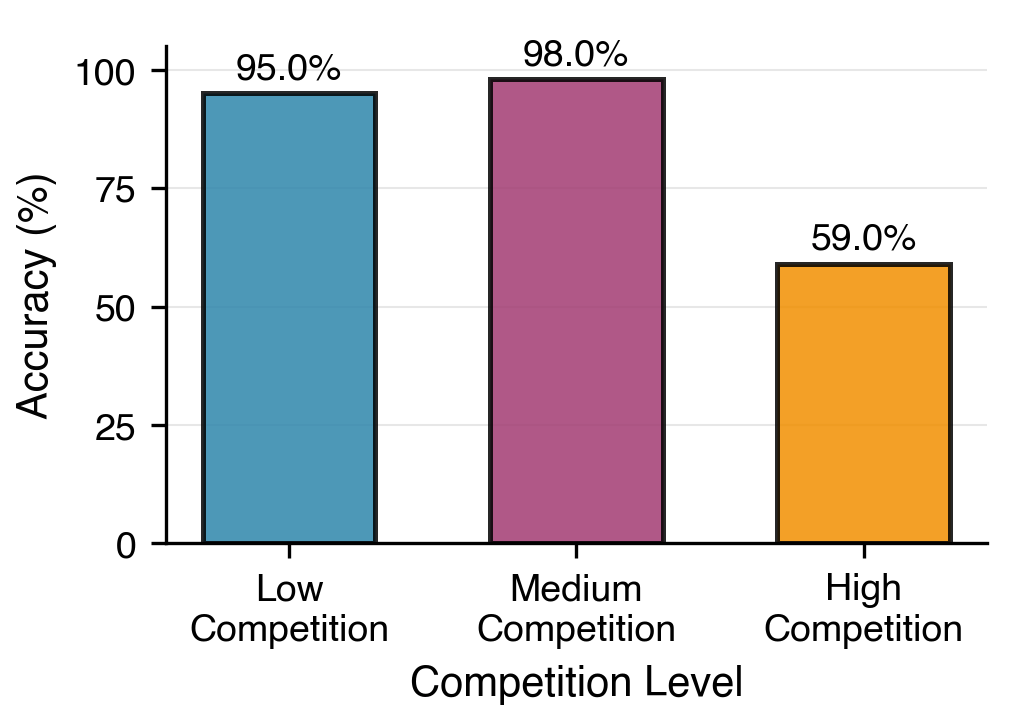
Figure 7: The effect of semantic competition on accuracy. Low Competition: <0.2 BGE cosine similarity; Mid Competition: 0.2–0.5; High Competition: >0.5.
See also: intra-family error distribution, transfer matrix
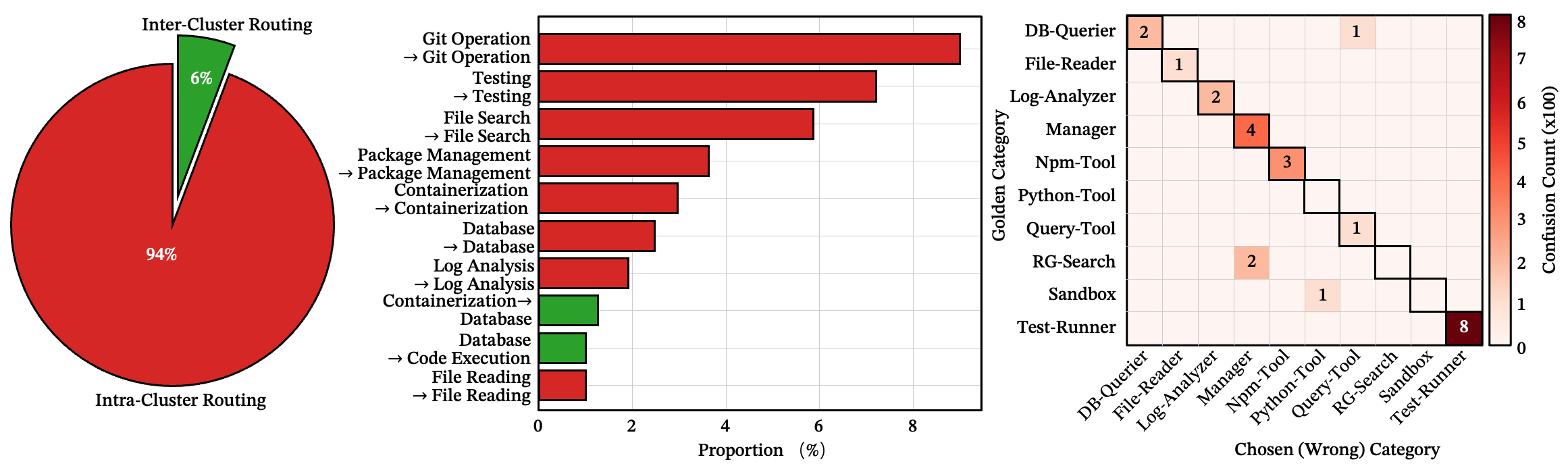
Figure 8: (a-b) Whether routing errors cross functional families. 94% remain within the same family. (c) Transfer matrix of routing errors. The strong block-diagonal structure confirms cluster isolation. Sparse bright spots outside the blocks indicate rare cross-cluster confusion.
The danger zone: similarity between 0.55 and 0.75
Here’s the counterintuitive part. Risk doesn’t increase monotonically with similarity. Near-identical skills (cosine > 0.75) are actually less dangerous — the model recognizes them as near-duplicates. Dissimilar skills (< 0.55) are easily dismissed.
The most hazardous region is the mid-to-high similarity band [0.55, 0.75). These competitors are similar enough to seem plausible, but different enough that the model can’t reliably tell them apart. They’re the uncanny valley of skill routing.
We also observe a counterintuitive search-depth effect: expanding the candidate pool from Top-20 to Top-50 actually increases error rates, because the additional candidates fall squarely in this dangerous band.
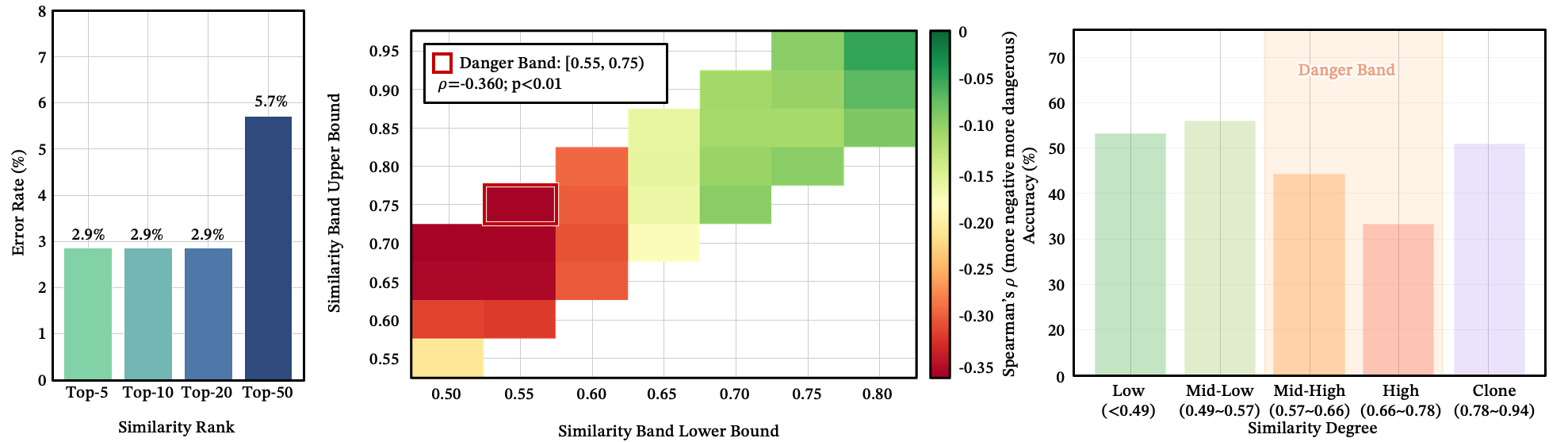
Figure 9: (a) Error rate by similarity rank — Top-50 introduces more errors than Top-20/10. (b) Heatmap of the dangerous competition band — [0.55, 0.75) shows the highest Spearman . (c) Similarity response curve across competition bands.
What to notice: the failure peak is in the middle-similarity band, not at maximum similarity (At least for a moment when creating a skill and publishing a task, you are "awake").
What this means in practice: Before adding a new skill, compute its cosine similarity against existing skills. If any neighbor falls in the [0.55, 0.75) range, either merge the two or rewrite both descriptions until they diverge below 0.55. Grow breadth (new functional domains) before depth (more skills in a crowded domain). For multi-step pipelines, re-inject the original user intent at mid-chain steps to shore up the weakest link.
The Boltzmann competition index
A skill doesn’t compete with the whole library — just its nearest neighbors. We capture this with a Boltzmann-style competition index:
where is the intrinsic advantage of the target skill and is the local pressure from surrounding competitors. The results suggest routing failure is better explained by local congestion than by scale alone.
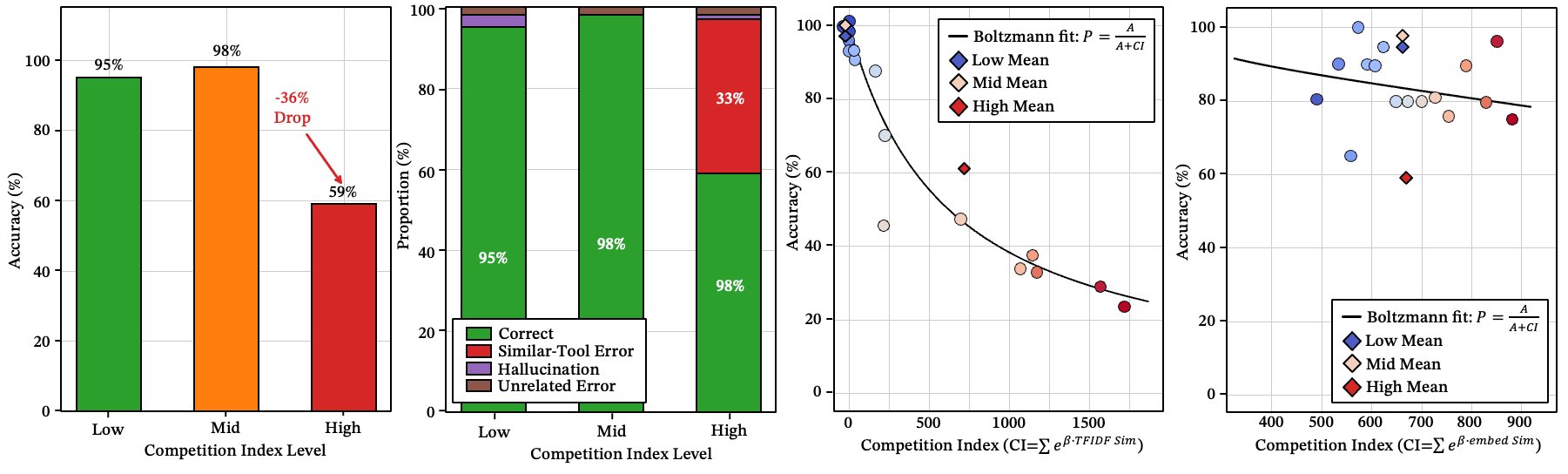
Figure 10: (a) The accuracy of different competition index level; (b) The error type distribution of different competition index level; (c-d) Boltzmann competition fits with competition index.
Three geometric patterns of confusion
Even within a single cluster, errors follow directional patterns shaped by description wording:
- Forward-dominant: Skill A’s broader description absorbs traffic from B, but not vice versa.
- Symmetric interference: Both skills compete bidirectionally — the router oscillates.
- Reverse-dominant: B absorbs A, opposite to intuition.
The key finding: accuracy under symmetric interference (8.3%) is far lower than under either dominance pattern (~33.5%). And this structure is determined by description wording, not skill function — changing a few keywords can convert symmetric interference into one-way dominance.
See also: failure geometry analysis
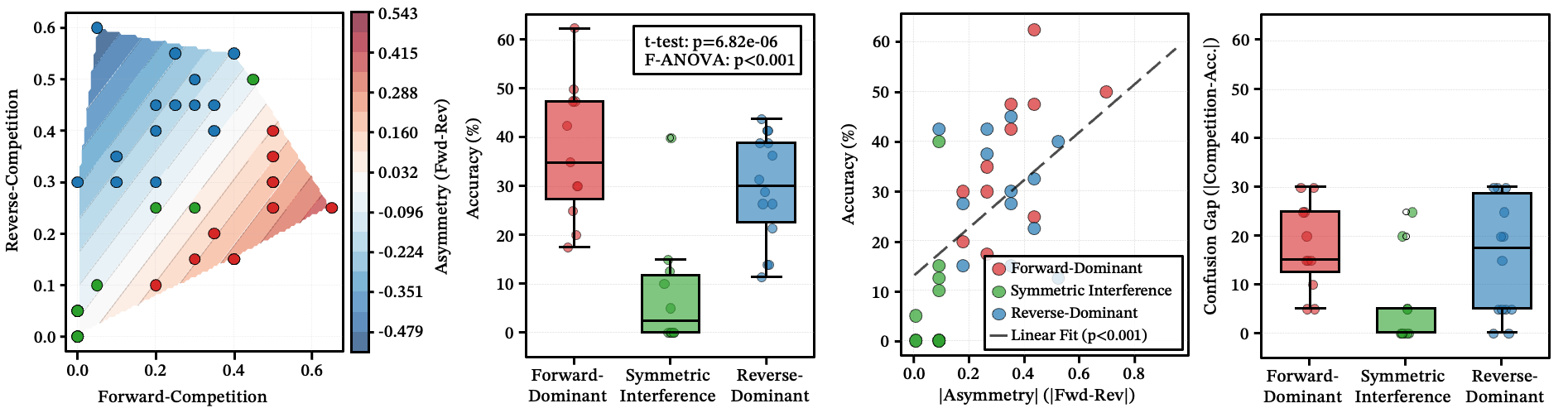
Figure 11: (a) Asymmetry density field — red = forward-dominant, blue = reverse-dominant, white = symmetric. (b) Accuracy by geometry type. (c) Asymmetry magnitude predicts accuracy. (d) Confusion gap is highest for symmetric interference.
The Rebound Effect: Accuracy Follows a U-Shape Across Pipeline Steps
Routing accuracy isn’t uniform across a multi-step chain. It follows a U-shape.
You’d expect accuracy to decay monotonically as the chain gets longer. It doesn’t. At , accuracy is about 65% at the first step, drops to 34% in the middle, and recovers to ~65% at the final step.
The mechanism: the first step benefits from the original user intent — the prompt is fresh and specific. The last step benefits from strong terminal constraints — the model knows it needs to converge and deliver a result. The middle steps are the fragile bottleneck, operating on compressed intermediate states where the original goal has faded and the model drifts into exploratory territory.
The implication: don’t evaluate a skill chain by looking only at the first and last steps. The middle is where things break.
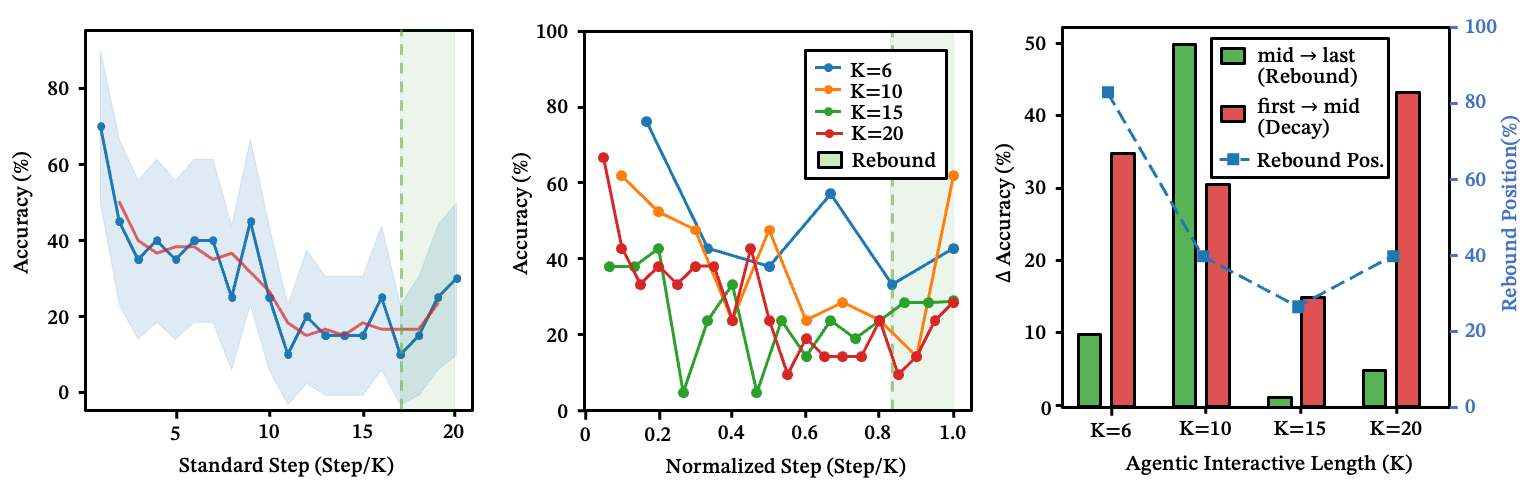
Figure 12: The rebound phenomenon of skill routing across pipeline steps.
The Black Hole Effect: What Happens When Semantic Anchors Disappear
Everything above assumes the user prompt contains clear operational anchors — “rebase onto main,” “run pytest with coverage.” What happens when those anchors are removed?
From 98% to 18%: the anchor-removal experiment
We tested two conditions on the same tasks: concrete prompts vs. vague rewrites. The results are stark.
Under concrete prompts, routing stays strong even at large scale:
| Library Size | Accuracy | Hijack Rate | Hallucination Rate |
|---|---|---|---|
| N=100 | 98.3% | 1.7% | 0% |
| N=150 | 99.2% | 0.8% | 0% |
| N=200 | 95.8% | 4.2% | 0% |
Under vague rewrites of the same tasks, the system collapses:
| Library Size | Accuracy | Hijack Rate | Hallucination Rate |
|---|---|---|---|
| N=100 | 33.3% | 66.7% | 0% |
| N=150 | 20.0% | 79.2% | 0% |
| N=200 | 18.3% | 81.7% | 0% |
Notice: hallucination rate stays at 0% in both conditions. The model never invents nonexistent tools. Instead, it selects plausible-looking alternatives from the existing library. The dominant failure mode is hijacking, not hallucination. And the degradation crosses cluster boundaries — we observe drift patterns like sql → data, git → memory, data → memory — the model falls back to skills that satisfy user intent at a more abstract level once operational detail is stripped away.
Semantic black holes: not where we expected
We initially tried to find “black holes” from embedding-space geometry — skills whose structural position should attract disproportionate traffic. It didn't work: structural indicators were uncorrelated with observed hijack rate.
So we asked a different question. We designed three increasingly abstract “god skills” and tested their hijacking power.
The finding: under concrete prompts, every god skill's hijack rate is 0%. No matter how abstract or all-encompassing a skill description is, clear operational intent in the prompt makes it invisible to the router.
A black hole only activates when two conditions are met simultaneously:
- The skill itself is highly abstract (an overly generalized container)
- The user prompt is highly vague (no operational anchors)
To be clear: black holes are not hallucinated tools — they are over-general skills already present in the library that absorb traffic when intent is ambiguous.
Under this dual trigger, hijack rate rises to 25-35% and grows with library size.
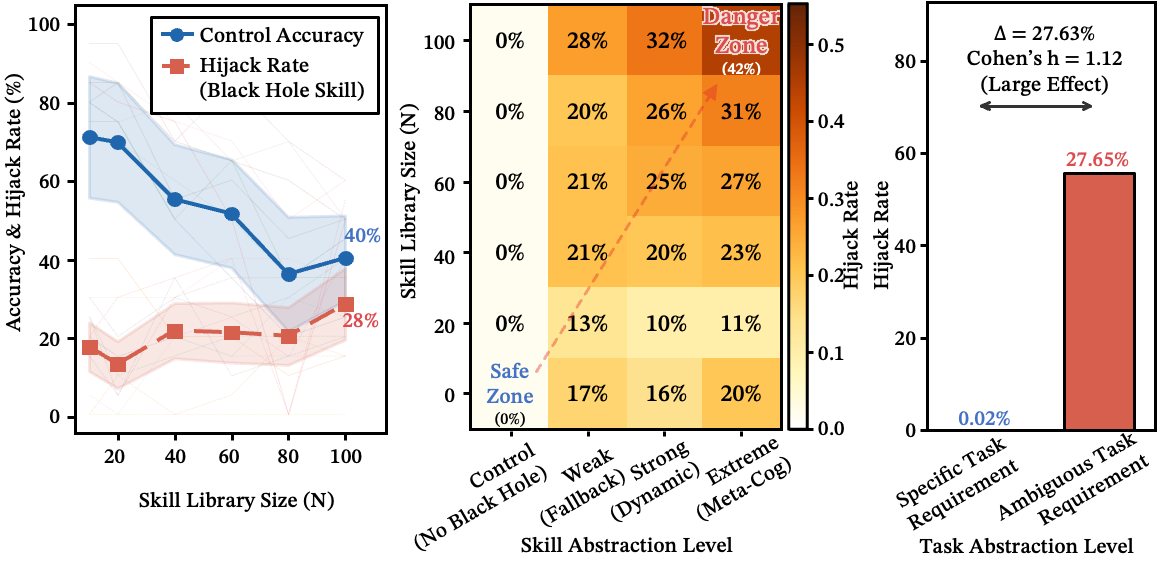
Figure 13: The dual-trigger mechanism. (a) As library size grows, control accuracy (blue) decays while hijack rate by an abstract "god tool" (red) rises; lines cross near , marking the onset of systematic hijacking. (b) Phase diagram of hijack rate as a function of skill abstraction level and library size — hijacking concentrates in the upper-right corner (high abstraction + large ), confirming neither condition alone is sufficient. (c) Task specificity provides complete immunity: concrete prompts yield 0% hijack rate regardless of skill abstraction, while ambiguous prompts reach 28%.
What to notice: the black-hole effect requires both an abstract skill AND a vague prompt — either condition alone is harmless.
See also: black-hole emergence with library scale
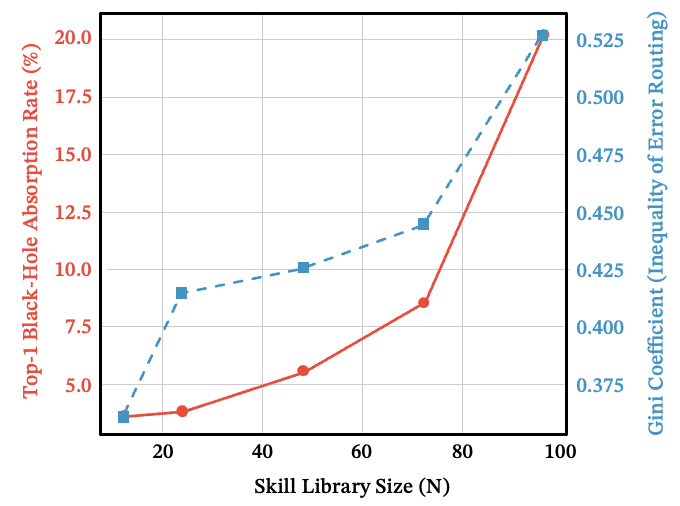
Figure 14: As grows, both the Top-1 black-hole absorption rate and the Gini coefficient of routing errors rise together — errors concentrate into a small number of attractor skills.
The full failure cascade
Routing failure escalates through distinct regimes as anchors degrade:
Local competition → Intra-family confusion → Cross-cluster drift → Black-hole capture
Each stage is more severe than the last, but each requires more specific conditions to trigger. Block the cascade early, and the later failure modes never appear.
What this means in practice: Eliminate abstract “god skills” from the flat routing pool entirely. If you need intent disambiguation, implement it as a dedicated pre-routing stage, not as a competing skill. The single most important variable across all experiments is prompt specificity — concrete operational anchors are the master switch that governs the entire failure cascade.
The Execution Paradox: Routing and Execution Obey Different Physics
Everything so far has been about selecting the right skill. But selecting and executing turn out to follow fundamentally different rules.
Routing without execution is memoryless
Routing looks memoryless only before execution injects state. Whether two skills get routed correctly together is essentially independent — . A logically coherent task description confers no synergistic routing bonus. Each decision is made in isolation.
See also: independence distribution figure
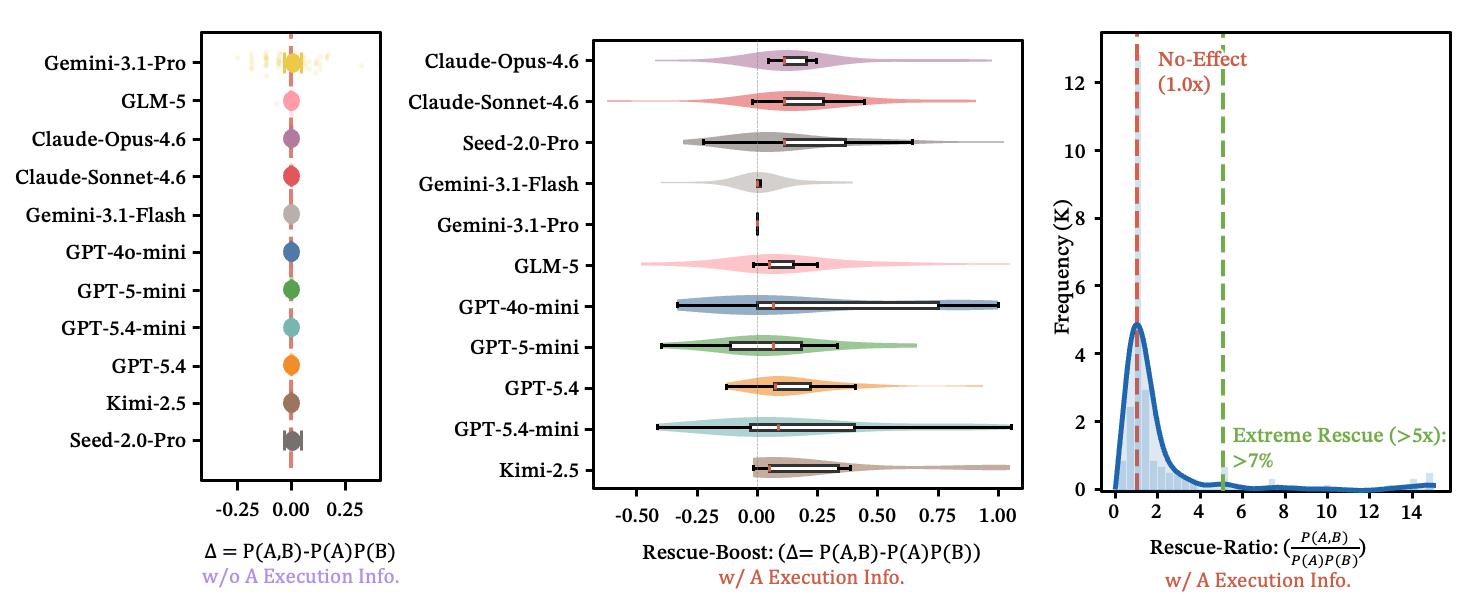
Figure 15: (a) Without execution, each row is a model; horizontal segments are 95% CIs of . Nearly all include zero. (b) With execution, different LLMs consistently offer positive rescue boost. (c) Over 7% of samples improve accuracy by 5x or more.
But execution rescues what routing cannot
Once upstream execution succeeds, the picture transforms. Steps that were nearly impossible to route independently () jump to 50–90% success after upstream completion. The median rescue factor is ~4x.
The intuition: successful execution compresses a vague search space into a concrete, anchored problem. This isn't better planning — it's state concreteness. The harder step B is on its own, the stronger the rescue:
This closes the loop with everything we've found: operational anchors are the master variable throughout the entire system. At the routing stage, they come from descriptions and prompts. At the execution stage, they come from the concrete states produced by upstream steps.
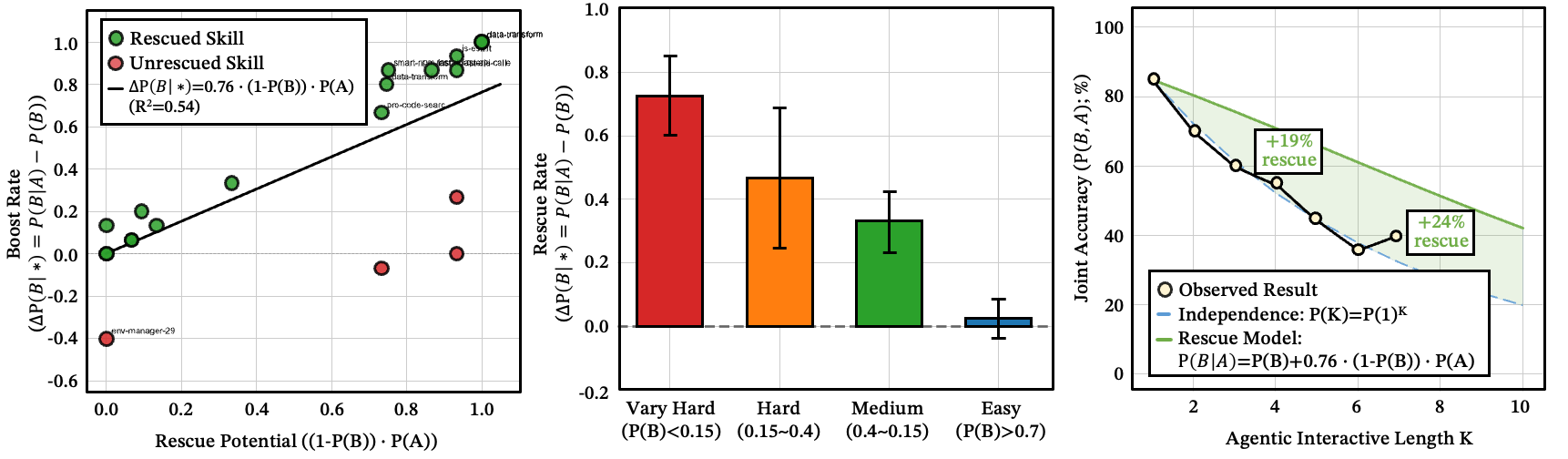
Figure 16: (a) Independent probability distributions for skills A and B; (b) vs. across 1,200 data points — most lie above the diagonal; (c) rescue ratio distribution with median ~4.09x; (d) empirical validation of the rescue formula; (e) rescue concentrates on difficult problems; (f) per-model violin plots.
What to notice: execution changes the state, so downstream selection is no longer independent — the rescue effect is strongest on the hardest problems.
Error propagation depends on coupling, not chain length
When an upstream step makes an error, does it poison everything downstream? It depends on the coupling between steps, not chain length.
- Tight data dependency: downstream performance drops by ~22%.
- Loose dependency: the system self-heals — downstream steps recognize flawed input and discard it, recovering ~10%.
- Complete independence: downstream is largely unaffected.
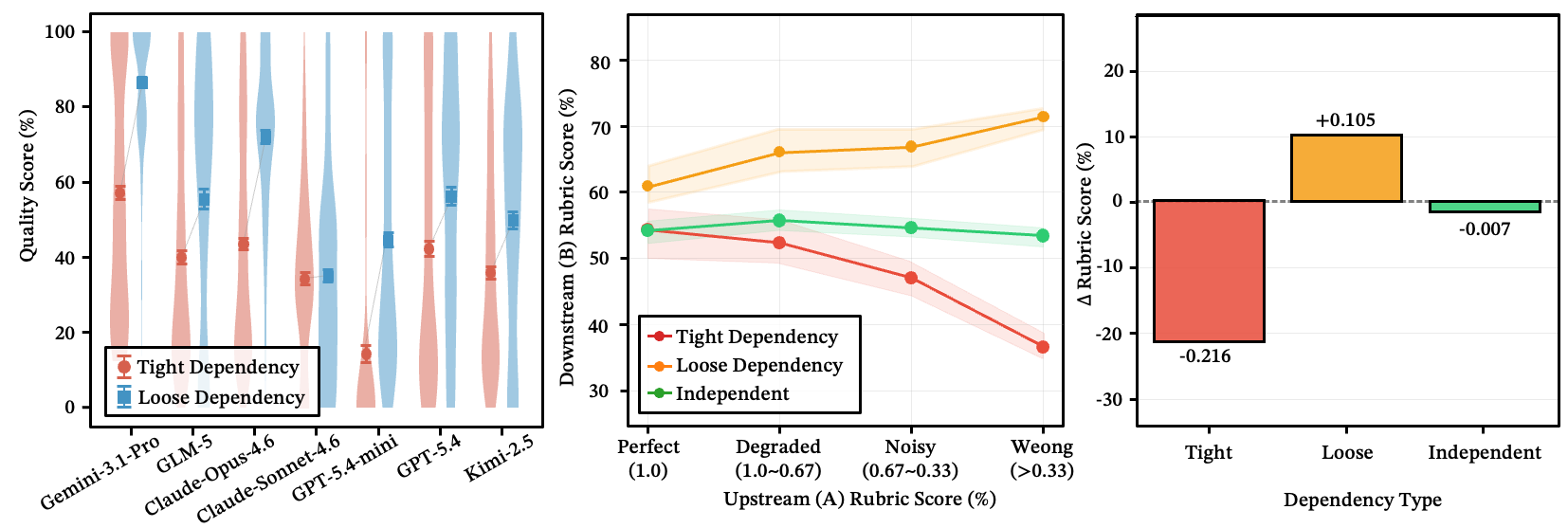
Figure 17: Error Propagation: (a-b) tight dependency causes steep quality degradation, loose dependency enables self-healing, independence is flat; (c) total score drop by type — tight: −0.216, loose: +0.105 (self-healing), independent: −0.007.
Strong-Tow vs. Weak-Drag: two execution regimes
When two skills execute jointly, one variable dominates: the capability gap between them.
- Strong-Tow (large gap): The stronger skill scaffolds the weaker one. Average synergy: +0.265.
- Weak-Drag (small gap, independent tasks): Peer-level skills compete for attention and output space. Average synergy: -0.115 — the majority perform worse than either skill alone.
If two tasks are both hard and independent, execute them sequentially — don't force them into the same generation.
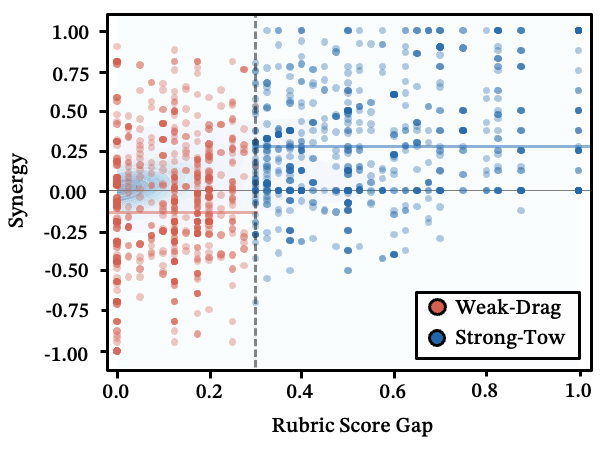
Figure 18: Capability gap vs. synergy score — the boundary between Strong-Tow and Weak-Drag.
What this means in practice: Treat routing and execution as separate optimization targets — improving one doesn't improve the other. Place a simple high-success step before a hard downstream step to exploit the rescue effect. Prefer loose coupling between steps so the system can self-heal. And pair strong skills with weak ones — never weak with weak.
What It All Means
Agent skill libraries are not passive registries. They are competitive semantic ecosystems governed by a small set of reproducible laws. Failure follows a cascade — logarithmic decay, local competition, cluster confusion, anchor loss, black-hole capture — and each stage requires more specific conditions than the last. Block the cascade early, and the later failure modes never appear.
Scaling agent capabilities is not an engineering problem you can brute-force. It's a physics problem with phase transitions and critical thresholds. Understanding these dynamics is the difference between an agent that gracefully handles 500 skills and one that collapses at 50.
We're releasing the full dataset and evaluation framework to help the community build agent systems that scale — not just in the number of skills they offer, but in the reliability with which they use them.
Key Takeaways
- The Logarithmic Wall is real. Every doubling of your skill library costs a fixed accuracy penalty — and it compounds across pipeline steps. At , three-step tasks are effectively broken.
- Competition is local, not global. A skill doesn't fight the whole library — just its semantic neighbors. The [0.55, 0.75) cosine similarity band is where routing goes to die.
- Abstract "god tools" are black holes. They only activate under ambiguous prompts, but when they do, they hijack 20-35% of all routing. The fix is architectural: remove them from the flat registry.
- Execution rescues routing — but not the reverse. A successful upstream step boosts downstream accuracy by ~4x. Design pipelines to put easy wins first.