
How to predict reasoning success before LLM inference?
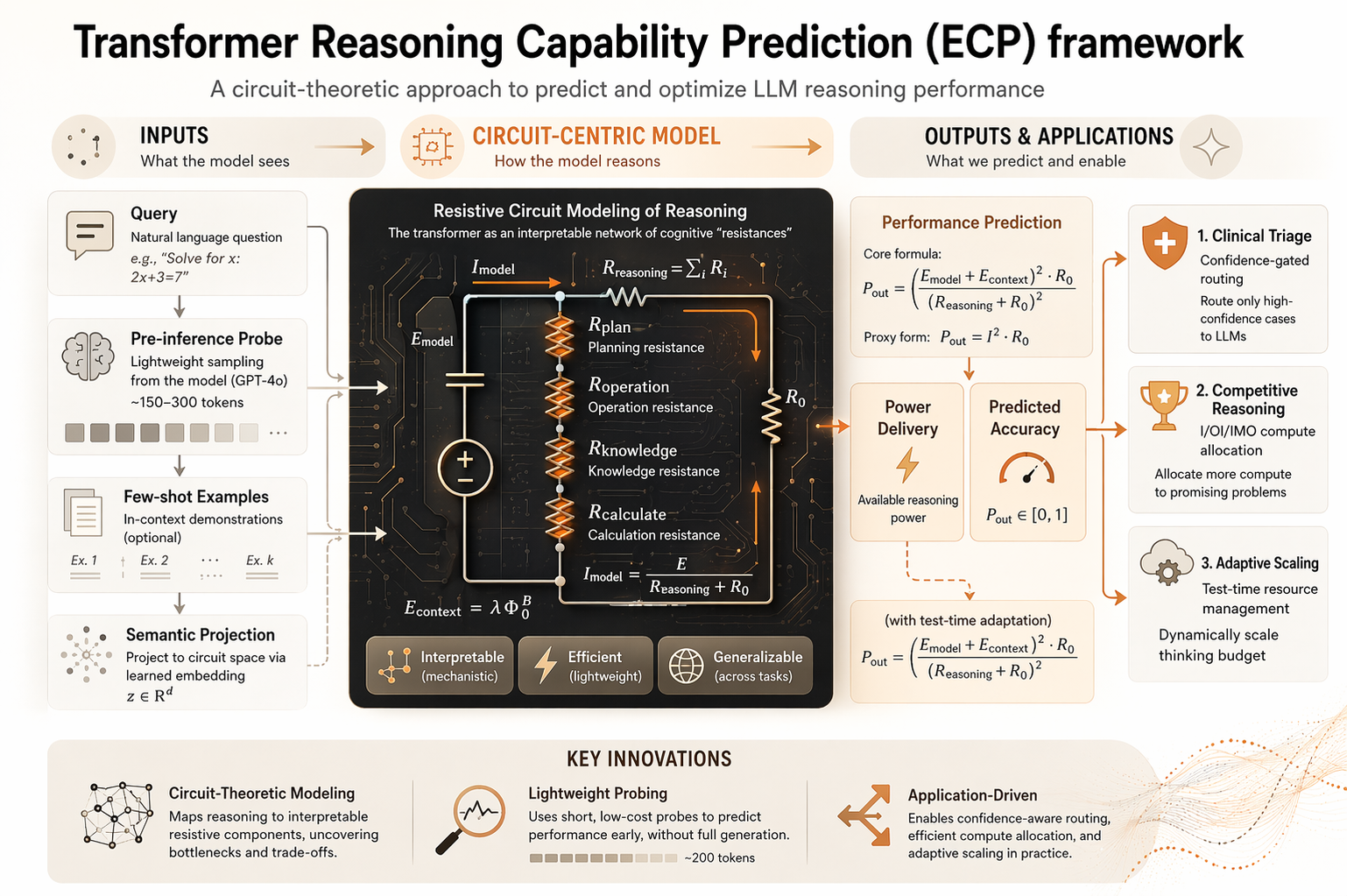
Table of Contents
- Table of Contents
- Motivation
- Intuition Behind the Circuit Law
- The Circuit Law: Formalism
- Why This Functional Form? Uniqueness Theorem
- How We Got Here: Discovery Narrative
- Experimental Validation
- Guiding Better Context Modeling as Circuit Operations
- Guiding Better Reasoning Strategies as Circuit Operations
- Why Not Simpler Alternatives?
- Applications
- Quick Start
- Current Supported Models
- Discussion
Motivation
When you ask an LLM a hard reasoning question, how do you know — before it even starts thinking — whether it will get it right?
Today, the honest answer is: you don't. You run the model, wait for the output, and then check. If it's wrong, you've already spent the compute. If it's a clinical diagnosis or a competition problem, you may not even know it's wrong until the damage is done.
We set out to change that. We wanted a lightweight, pre-inference signal that tells you: "This question is too hard for this model in this context — escalate, retrieve more evidence, or allocate more compute."
The surprising discovery is that such a signal exists, and it follows a precise quantitative law borrowed from an unexpected source: electronic circuit theory.
Intuition Behind the Circuit Law
A transformer solving a multi-step reasoning problem faces two opposing forces:
- Contextual support, pushing it toward the answer (like voltage driving a circuit)
- Reasoning complexity, pulling it back (like resistance dissipating energy)
The balance between these — not either alone — determines success. And that balance follows the same power-delivery equation that governs how much useful work an electrical circuit can do.
This isn't a loose metaphor. We prove it is the unique functional form consistent with four structural properties of autoregressive transformers.
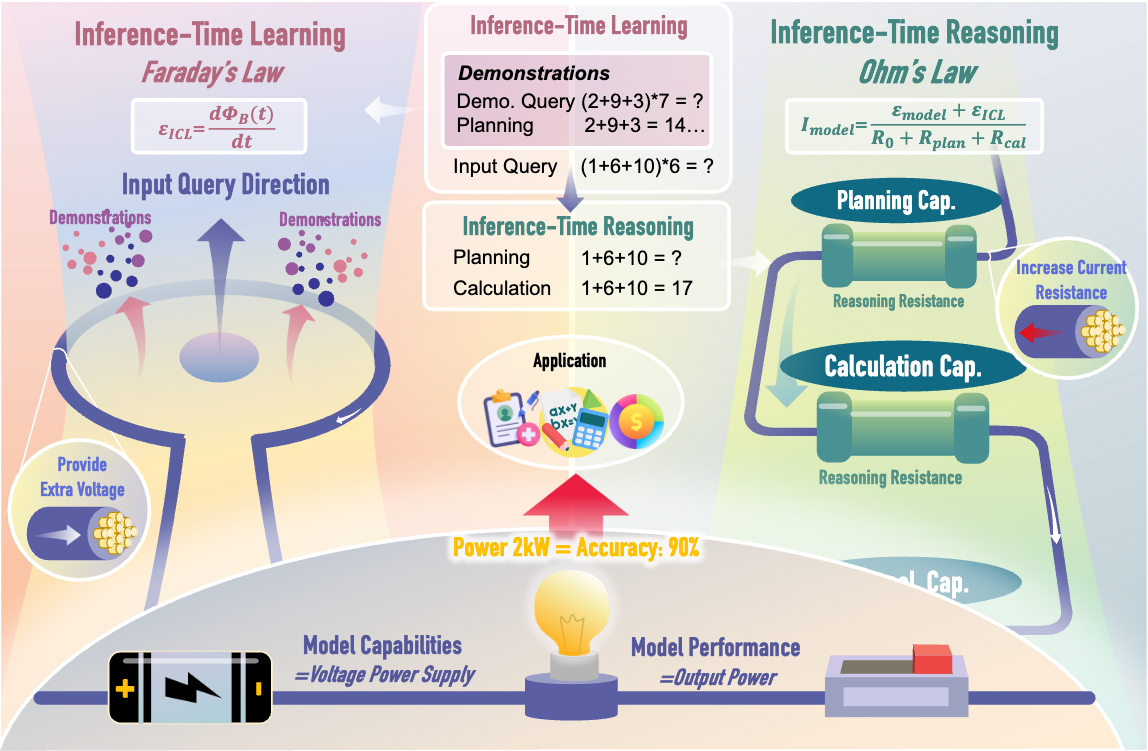 Figure 1: Pre-inference prediction accuracy (R² ≥ 0.95) holds robustly across in-domain and out-of-distribution settings.
Figure 1: Pre-inference prediction accuracy (R² ≥ 0.95) holds robustly across in-domain and out-of-distribution settings.
The Circuit Law: Formalism
The model's success probability is governed by:
Key components:
| Symbol | Circuit Analogue | Meaning | How Obtained |
|---|---|---|---|
| Battery EMF | Intrinsic model capability | Fitted per model (one scalar) | |
Contextual drive (Inference-Time Learning):
Reasoning load (Inference-Time Reasoning):
Each component is estimated from the query alone via a lightweight pre-inference probe (GPT-4o, ~150–300 tokens), independent of the target model's generations.
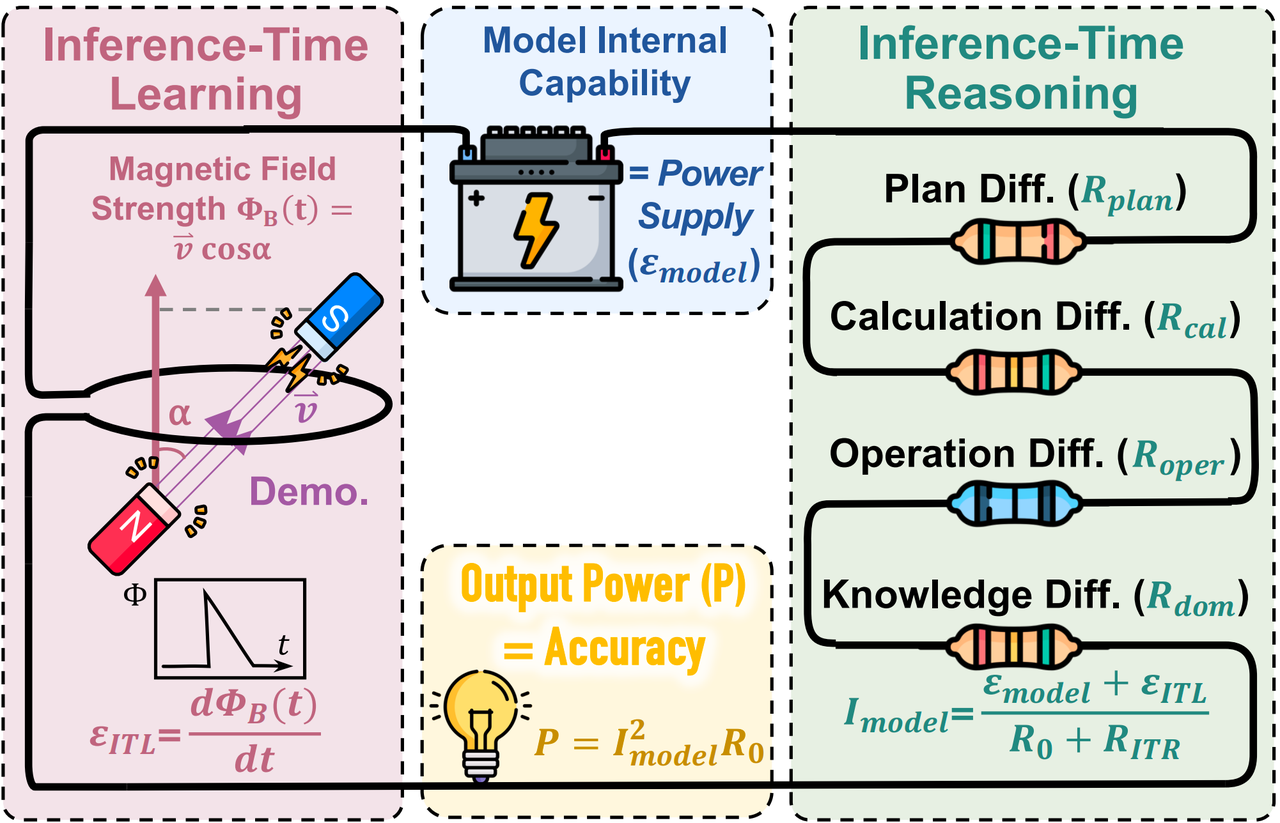 Figure 2: Circuit analogy for LLM reasoning. Contextual support (EMF) and reasoning complexity (resistance) determine delivered power (success probability).
Figure 2: Circuit analogy for LLM reasoning. Contextual support (EMF) and reasoning complexity (resistance) determine delivered power (success probability).
Why This Functional Form? Uniqueness Theorem
A natural question: why this particular form? Could a simpler model work just as well?
We prove the circuit law is the unique functional form consistent with four structural properties any autoregressive transformer must satisfy:
-
Additivity of load: Composing two independent reasoning steps increases difficulty additively: . This follows from token-by-token generation — each step compounds error accumulation.
Theorem (Uniqueness). Any continuous function satisfying properties 1–4 must take the form:
up to monotone rescaling of the output. In other words, the circuit law is the only admissible predictor — not chosen from a model zoo, but derived from first principles.
This has a practical consequence: there is no need to search over functional forms or neural architectures. The physics of the transformer dictates the prediction equation.
How We Got Here: Discovery Narrative
Initially, we tried standard approaches to predict LLM reasoning success:
- Logistic regression on handcrafted difficulty features
- Neural calibrators trained post-hoc on model outputs
- Self-assessment — asking the LLM to rate its own confidence
None achieved satisfactory accuracy (R² < 0.7) or transferred to unseen tasks.
The breakthrough came unexpectedly. When we plotted accuracy curves against reasoning depth, they resembled power dissipation curves in electrical engineering. This insight led us to model the reasoning process as an electrical circuit and derive a unique functional form from first principles.
The result: R² ≥ 0.95 in-domain, with robust transfer across unseen tasks and models.
Experimental Validation
Scale: 70,000+ instances · 350+ tasks · 9 LLMs · 8 random splits per setting
Models: GPT-4o, GPT-4o-mini, GPT-3.5-Turbo, DeepSeek-R1 / V3, Gemini-2.0 / 1.5-Flash, Qwen2.5-7B / 32B, Qwen3-32B
Benchmarks: BBH (27 tasks) · MMLU (57) · MMLU-Pro (14) · MATH (7) · GSM8K / BigGSM / BigGSM++ · GPQA / SuperGPQA (300+) · MedQA / PubMedQA / MedMCQA · HotpotQA · MGSM (11 languages)
Pre-Inference Prediction Accuracy
| Setting | MSE | MAE | R² |
|---|---|---|---|
| In-domain | 0.0005 | 0.0174 | 0.9553 |
| OOD-Task (held-out tasks) | 0.0031 | 0.0482 | 0.9087 |
| OOD-Model (held-out LLMs) | 0.0033 | 0.0507 | 0.8493 |
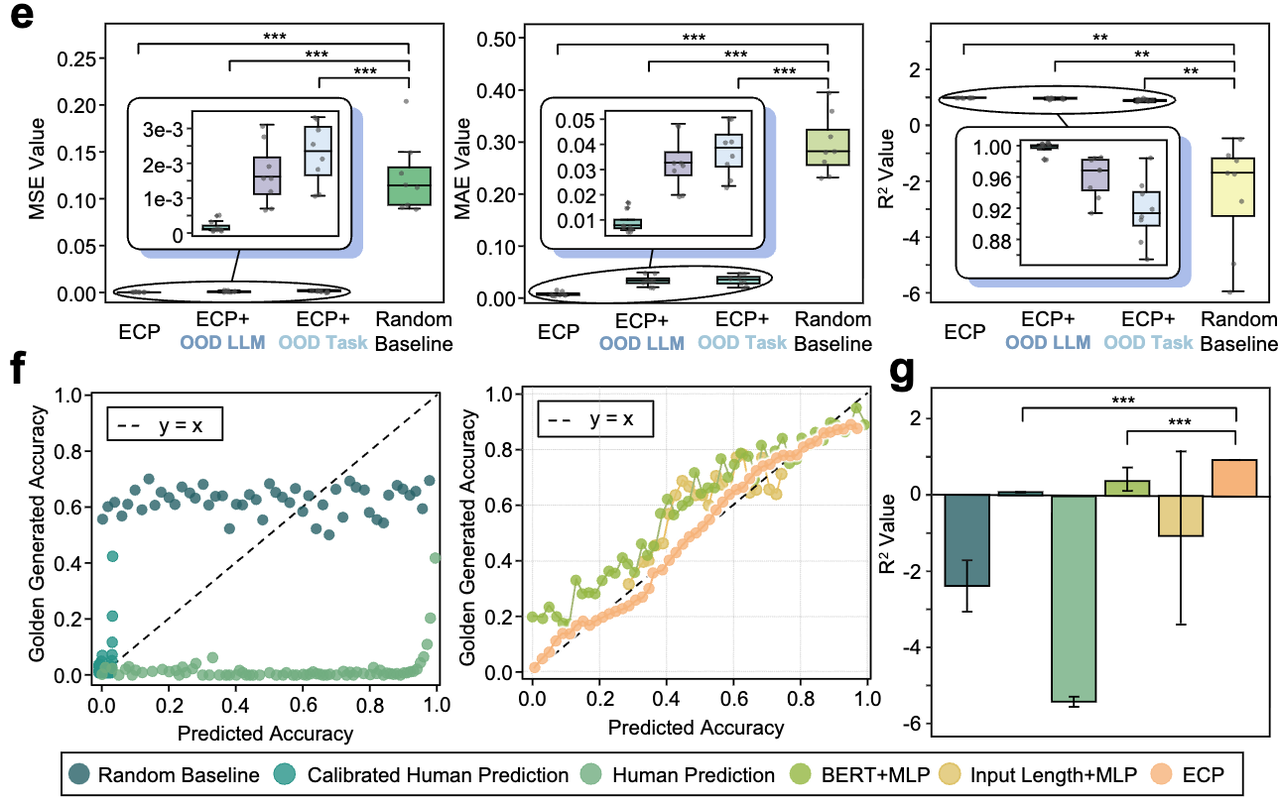 Figure 3: Circuit law predictions (R² ≥ 0.95) generalize robustly to held-out tasks and models.
Figure 3: Circuit law predictions (R² ≥ 0.95) generalize robustly to held-out tasks and models.
Circuit Compositionality
The circuit law yields two falsifiable structural predictions — both confirmed:
Series composition: As reasoning length grows, accumulates linearly and accuracy decays as . Empirical fit: R² > 0.95. This explains why extremely long reasoning chains degrade — the signal attenuates before completion.
Parallel composition (self-consistency): Running concurrent chains reduces effective resistance to . However, inter-sample correlations limit the benefit: effective independent trajectories scale as , not . This yields a first-principles explanation for widely observed diminishing returns in inference-time scaling, and an optimal stopping rule for instance-specific sample budgets.
 Figure 4: Series and parallel circuit compositions explain reasoning length degradation and self-consistency scaling limits.
Figure 4: Series and parallel circuit compositions explain reasoning length degradation and self-consistency scaling limits.
Guiding Better Context Modeling as Circuit Operations
Context helps only when meaningfully aligned with the query. Rather than treating demonstrations as extra prompt content, view them as circuit inputs that can support or disrupt reasoning:
| Strategy | Circuit Operation | Measured Effect |
|---|---|---|
| Zero-shot baseline | Remove demonstrations | ECP score still tracks accuracy |
| Projection-length retrieval | Select aligned support signals | Best agreement with task performance |
| Euclidean retrieval | Standard geometric similarity | Worse than projection length |
| BGE Encoding for RAG | Improve semantic support construction | Better theory–performance alignment |
| Meta-Recognition Encoding RAG | Fine-grained support representations | Higher theoretical power and accuracy |
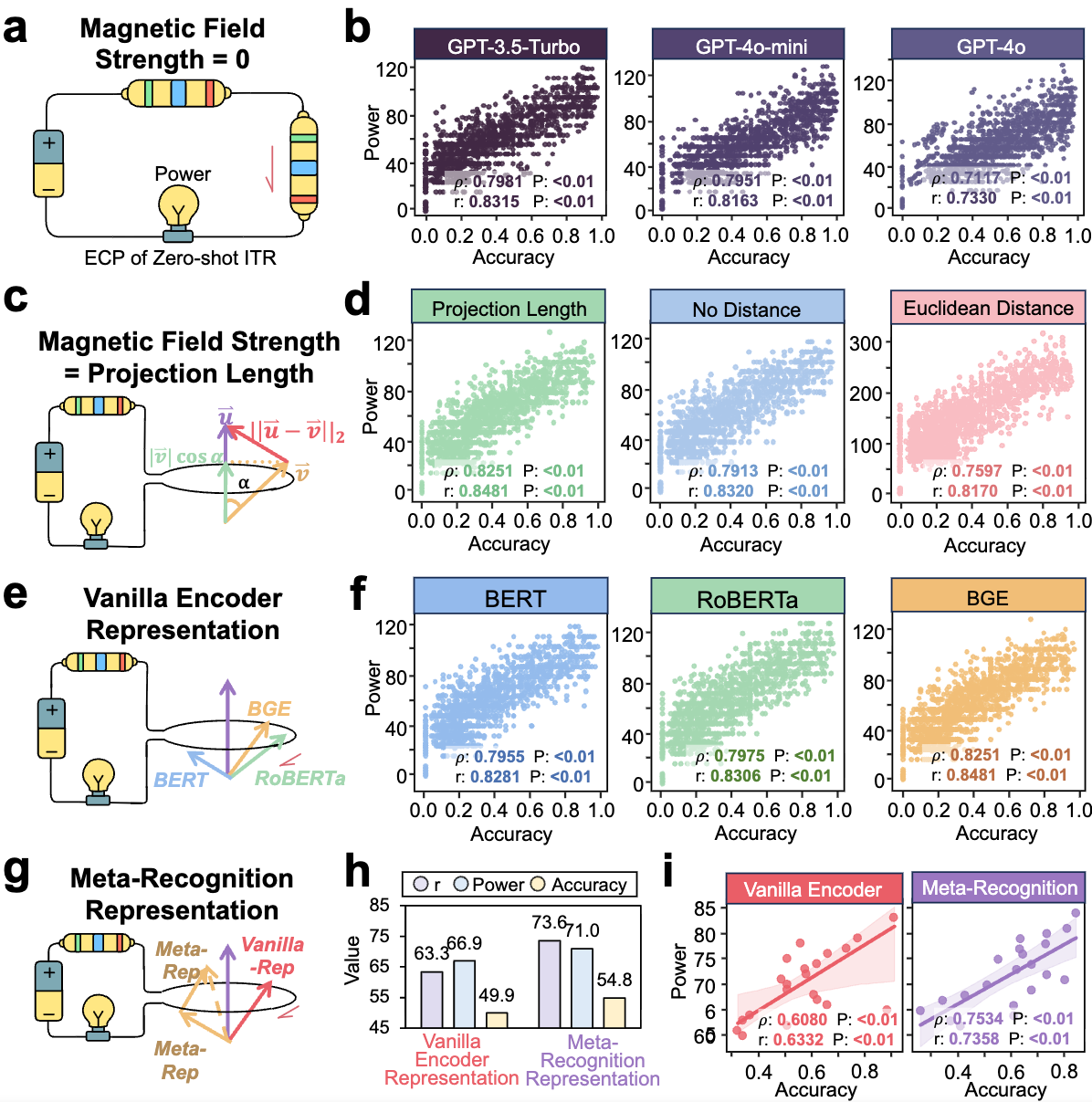 Figure 5: Projection-length retrieval maximizes alignment between contextual drive and actual task performance.
Figure 5: Projection-length retrieval maximizes alignment between contextual drive and actual task performance.
Guiding Better Reasoning Strategies as Circuit Operations
Every major prompting strategy maps onto a specific circuit operation with quantitatively predicted effects:
| Strategy | Circuit Operation | Measured Effect |
|---|---|---|
| Chain-of-Thought | Reduces via decomposition | R: 4.40 → 3.97 ⬇️ Acc: 33.6% → 41.7% ⬆️ |
| Few-shot (top-k) | Increases via semantic alignment |
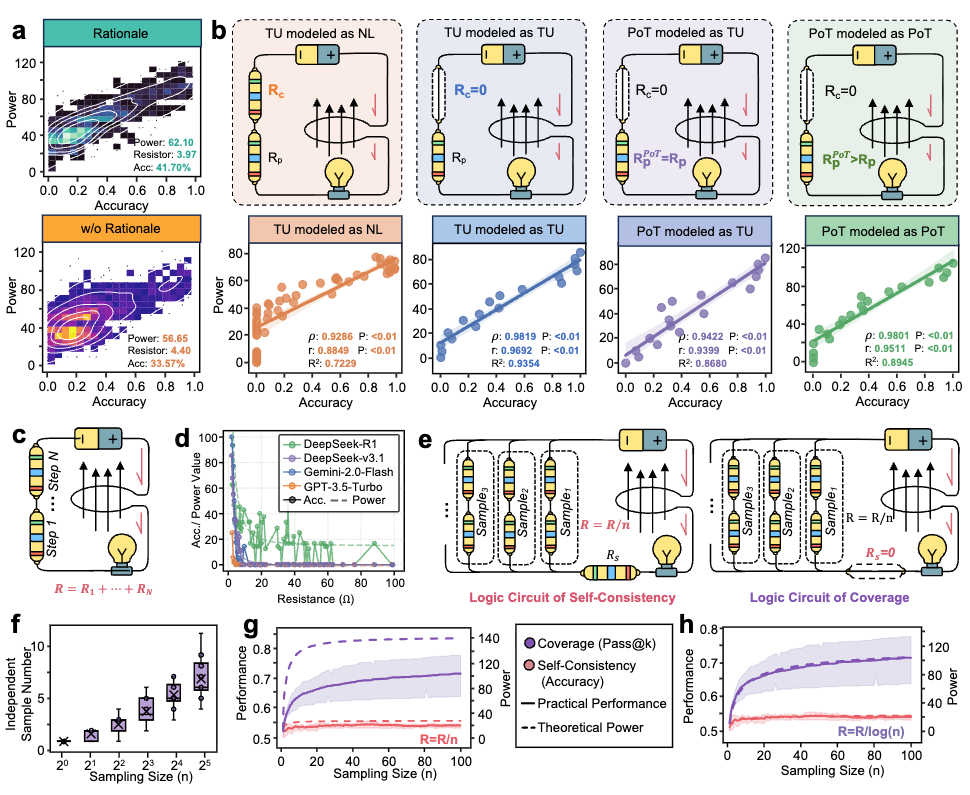
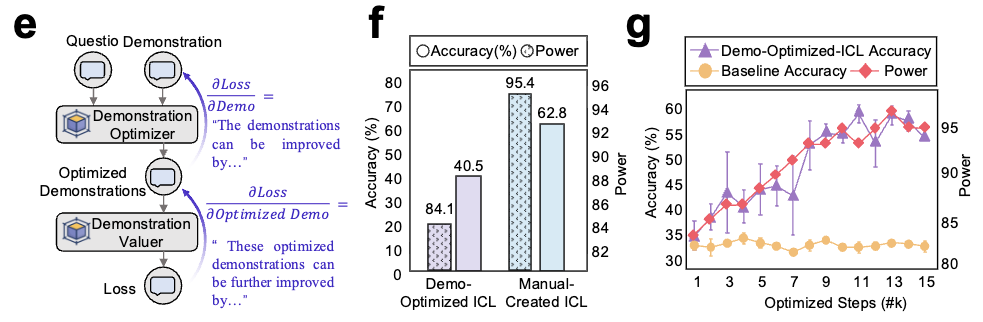 Figure 6: Prompting techniques reduce reasoning load or increase contextual drive, with effects quantitatively predicted by circuit law.
Figure 6: Prompting techniques reduce reasoning load or increase contextual drive, with effects quantitatively predicted by circuit law.
Why Not Simpler Alternatives?
Readers naturally ask: why not use model confidence, logprobs, or learned difficulty estimators?
| Alternative | Why It Falls Short |
|---|---|
| Model self-confidence (logprobs) | Poorly calibrated for reasoning tasks; R² < 0.45; no transfer to new models |
| Linear regression on features | Violates impedance matching; misses interaction term; R² < 0.65 |
| Neural calibrator (post-hoc) | Overfits to training distribution; R² drops to 0.52 on OOD tasks |
| Scaling laws | Predicts training loss, not per-instance reasoning success; orthogonal problem |
| Output-length heuristic | Weak correlation (r < 0.53); post-hoc only; no pre-inference signal |
The circuit law is not just better — it's the only form consistent with transformer structure.
Applications
Because ECP produces a portable, calibrated pre-inference difficulty signal, it serves as a control input for real-world systems — routing compute, triggering retrieval, or escalating to human oversight.
Clinical Diagnosis: Confidence-Gated Triage
We evaluate ECP as a decision layer in a human-in-the-loop medical workflow spanning 1,914 cases across three benchmarks (MedQA, PubMedQA, MedMCQA):
| Stage | Action | Trigger |
|---|---|---|
| 1. Pre-inference risk assessment | Compute from patient history (context) and diagnostic reasoning steps (load) | All cases |
| 2. Adaptive retrieval | Retrieve clinical guidelines & request better LLMs to boost ; require human quick re-check |
Results: At >98% diagnostic accuracy, the confidence-gated policy reduces total cost by ~30% vs. fully manual review and ~15% vs. human–Gemini baseline. Calibration: MSE = 0.0082, MAE = 0.0726, R² = 0.9291 (GPT-4o).
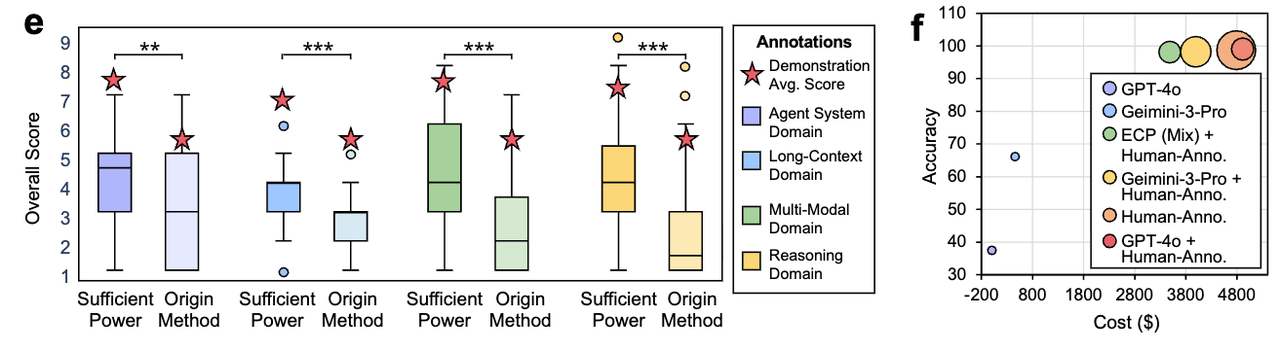
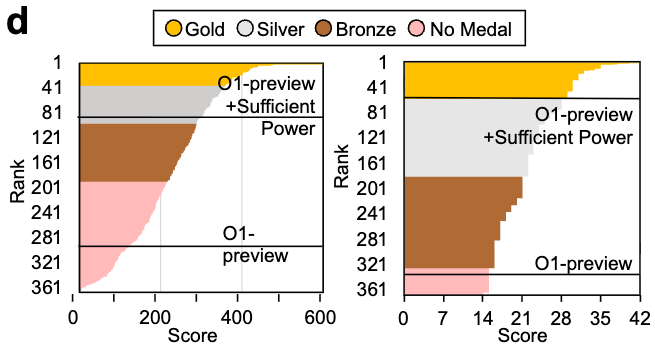 Figure 7: ECP can well guide performance improvement and cost reduction, where Confidence-gated triage reduces cost by 30% while maintaining >98% diagnostic accuracy.
Figure 7: ECP can well guide performance improvement and cost reduction, where Confidence-gated triage reduces cost by 30% while maintaining >98% diagnostic accuracy.
Competitive Reasoning: IOI & IMO
Using burden-guided compute scaling (o1-preview) — identifying the dominant resistance bottleneck per instance and allocating additional compute there:
- IOI 2024: 🥈 Silver medal — surpassed ~80% of human contestants
- IMO 2024: 🥉 Bronze medal — surpassed ~80% of human contestants
- AI-Scientist: Expert-rated novelty and impact scores increased by >1.0 point
Discussion
Why Circuit Theory?
The circuit law emerges not from curve-fitting but from first principles. Transformers are fundamentally sequential processors: each reasoning step compounds the opportunity for error, just as each resistor in a series circuit compounds voltage drop. The power-delivery equation naturally captures this trade-off between driving force (context) and accumulated load (reasoning complexity).
This insight reframes a long-standing puzzle in LLM scaling: why do few-shot examples help, but with diminishing returns? Why do longer reasoning chains degrade? Why does self-consistency plateau? The circuit law answers all three through a single, unified framework.
Implications for LLM Design
- Context is not free. The circuit law quantifies exactly when additional context stops helping — at the impedance-matched point . Beyond this, the task overwhelms the model regardless of how much evidence you provide.
- Reasoning decomposition is powerful. Chain-of-thought works because it reduces by breaking complex steps into simpler ones. The circuit law predicts the exact magnitude of this benefit.
Broader Impact
ECP democratizes reasoning-aware compute allocation. Clinical systems can triage cases by predicted difficulty. Educational platforms can adapt problem difficulty in real-time. Research teams can allocate limited GPU budgets more efficiently. The 30% cost reduction in medical diagnosis is just the beginning.