
技能越多,效果越差?Agent 技能库背后的隐藏本质
技能越多,效果越差?Agent 技能库背后的隐藏本质
我们给 Agent 配备了数百个真实技能,期望它们变得更聪明。结果恰恰相反——它们开始选错工具,而且这些失败并非随机,而是遵循精确、可预测的模式,更像物理学中的相变,而非软件 Bug。
300 万次 API 调用,11 个主流大模型,989 个真实技能。我们发现了一组支配 Agent 技能生态系统在规模化运行时的经验定律——它们挑战了 Agent 设计中的一个核心假设:更多工具 = 更好表现。
测试模型:GPT-4o-mini · GPT-5-mini · GPT-5.4-mini · GPT-5.4 · Claude Sonnet 4.6 · Claude Opus 4.6 · Gemini 3.1 Pro · Gemini 3.1 Flash Lite · GLM-5 · Kimi K2.5 · Doubao Seed 2.0 Pro

图 1:流水线深度 与技能库规模 的性能等高线图。清晰的安全区和死亡区自然浮现——当 和 同时增大时,系统迅速进入不可靠区域。
图 1 为概念示意图;后续各图将用实验数据逐一验证该图的每个部分。
悖论在于:一个包含 1,000 个技能的库可以实现近乎完美的路由准确率——前提是技能在语义上充分分离。但只要在同一语义邻域中塞入 30 个相似技能,准确率就会崩溃。瓶颈不在于你有多少工具,而在于技能空间中最拥挤的角落有多拥挤。
每个新技能都增加了能力,但也增加了竞争。这种竞争遵循我们现在可以描述、预测并加以防范的规律。
对数墙:路由准确率为何存在硬性天花板
当你向技能库中添加更多技能时,单步路由准确率如何变化?
答案出奇地干净。技能库每翻一倍,就会带来固定的准确率损失。在所有 11 个模型和多样化的真实技能集上,这一关系以 成立:
这不是随机退化——而是一个根本性的天花板。路由器在有限的表征能力下运行,每个技能描述都在争夺相同的语义资源。随着库的增长,任何单个技能的显著性都在持续被稀释。可区分性本身就是一种有限资源。
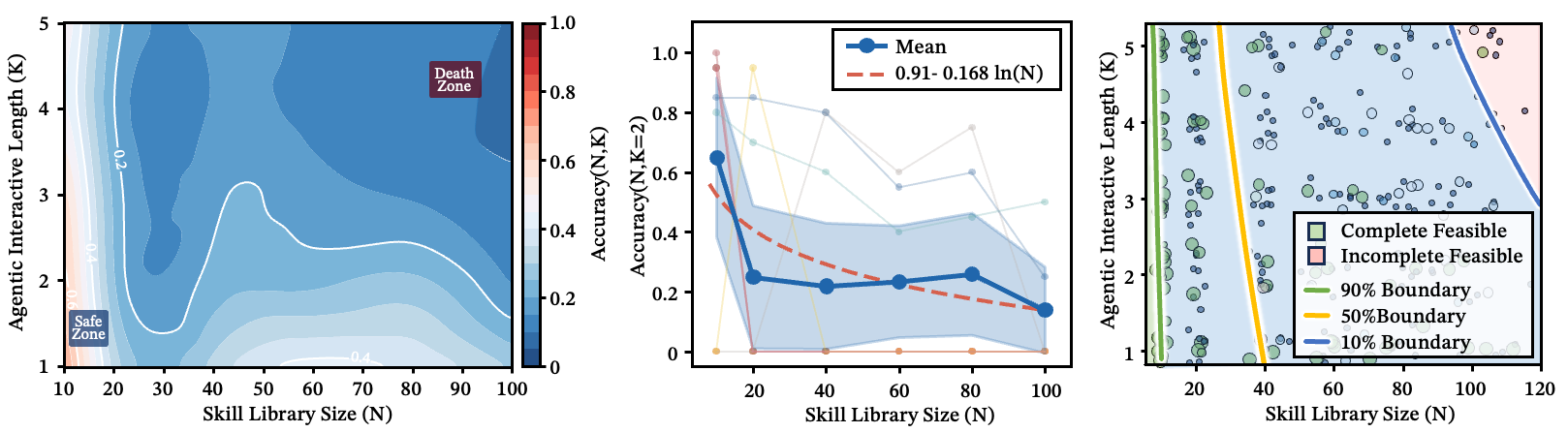
图 2:11 个模型的聚合拟合曲线。不同模型有不同的衰减斜率,但对数形式是普适的。
多步流水线中的复合问题
当 Agent 链式调用多个技能时,情况急剧恶化。三步各 85% 的准确率并不会给你 85% 的端到端成功率——而是 61%:
在 、 时,单步约 85% 的准确率仅产生约 20% 的端到端成功率。一个在隔离测试中看起来正常的路由器,在真实流水线中已经处于不稳定区域。经验曲线的衰减甚至比理论预测更陡峭,原因在于错误级联和上下文污染。
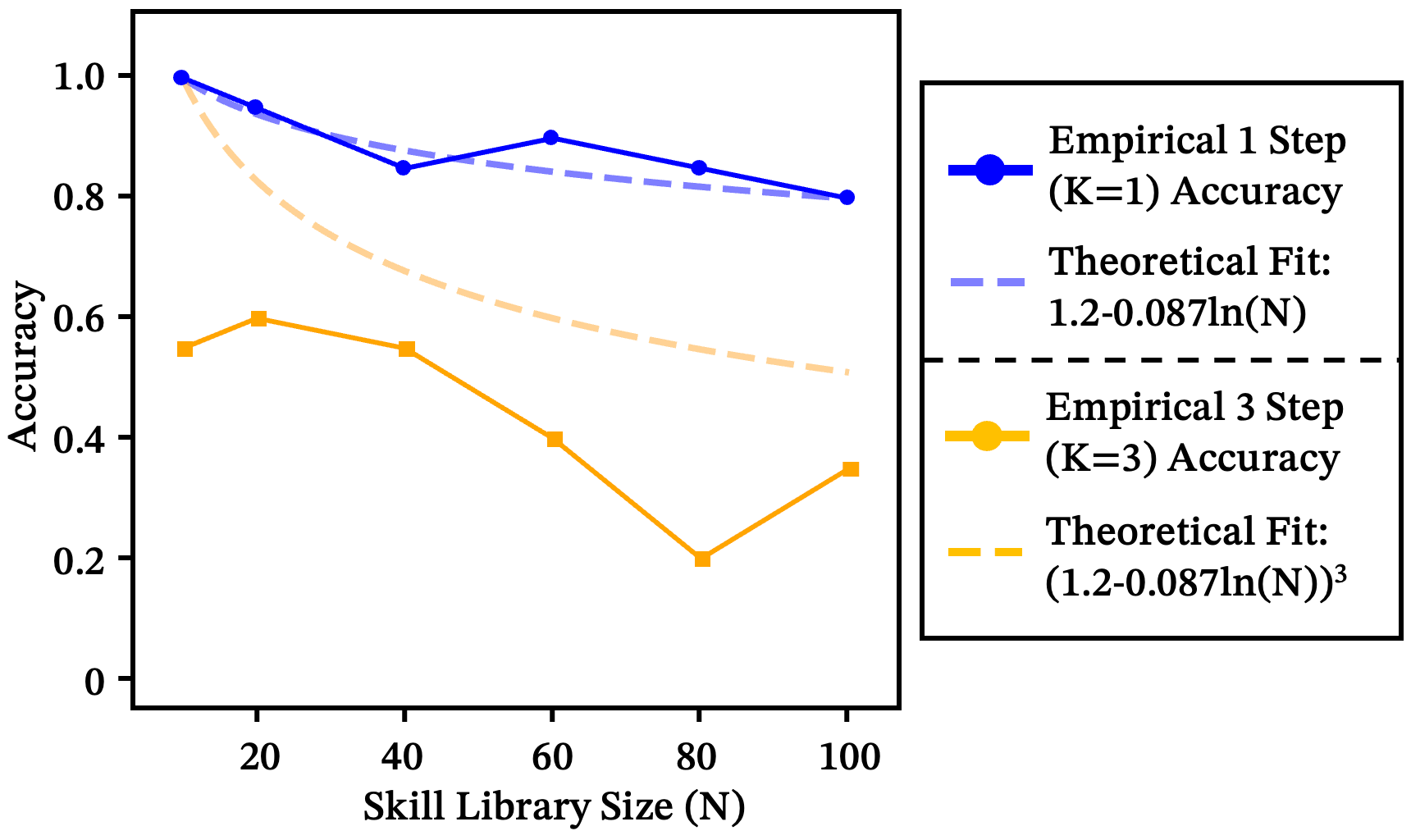
图 3:理论值(虚线)vs. 经验值(实线)的衰减对比。
什么样的技能描述是好的?
长度很重要——但有上限。 更长的描述能提升路由性能,但收益在约 280 token 处趋于平稳。低于约 236 字符时,存在明显的准确率断崖。
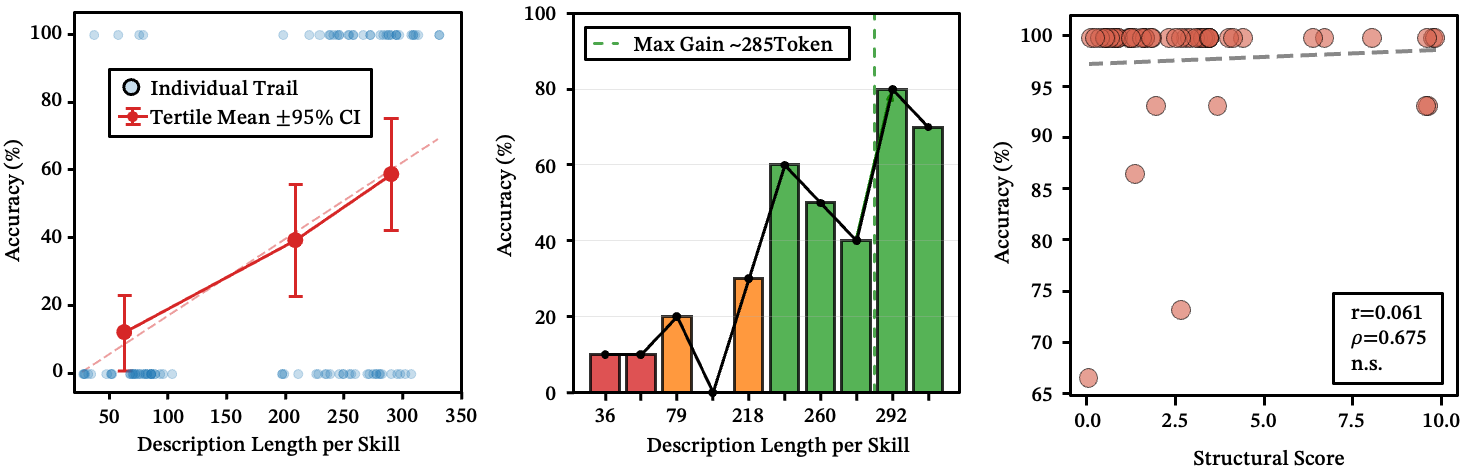
图 4:(a-b) 描述长度 vs. 路由准确率。236 字符处出现明显分界。(c) 结构化评分 vs. 路由准确率——无显著相关性。
表面层级的结构化无济于事。 技能描述往往采用高度结构化的格式。我们测试了更好的格式是否能改善路由,通过对描述的结构质量进行评分。与准确率的相关性?统计上不显著。路由器不在乎你的项目符号列表。
系统性消歧才是真正有效的手段。 如果对数墙是坏消息,那么好消息是:技能描述质量是系统设计者可用的最大杠杆。差距是巨大的——在 时,精心编写的描述(L5)保持 72% 的准确率,而最简标签(L1)降至 11%。这是 61 个百分点的差距。
我们定义了五个质量等级:
- L1:仅技能名称
- L2:添加一句功能摘要
- L3:添加目标对象和典型操作
- L4:添加适用约束和使用示例
- L5:添加边界条件和反例(何时不应调用该技能)
从 L4 到 L5 的跃升最具启发性。两个等级的 token 数相近,但 L5 获得了约 7% 的准确率提升。差异不在于长度——而在于反例子句("不要将此技能用于 X;请改用 Y")。这恰恰是打破相似技能间歧义的关键信息。
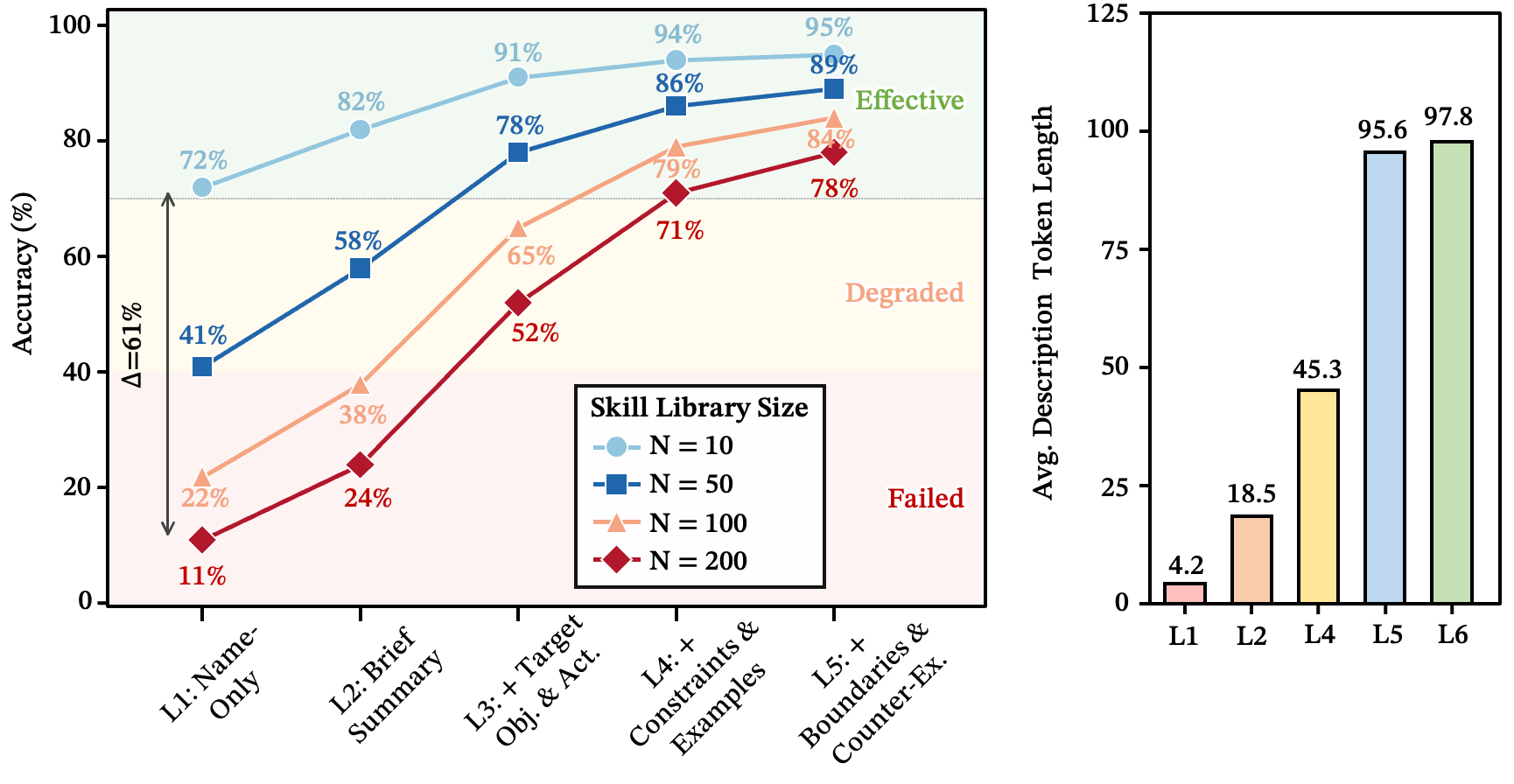
图 5:五个描述质量等级在 下的 Top-1 路由准确率。虚线标记 70% 部署阈值。
好的描述不仅仅是描述——它们在语义空间中宣示领地。 重要的不是一个描述在孤立状态下读起来多"清晰"——而是它相对于竞争者占据了多少语义领地。我们称之为语义半径,它在所有 11 个模型中都正向预测路由准确率。
另见:语义半径 vs. 路由准确率
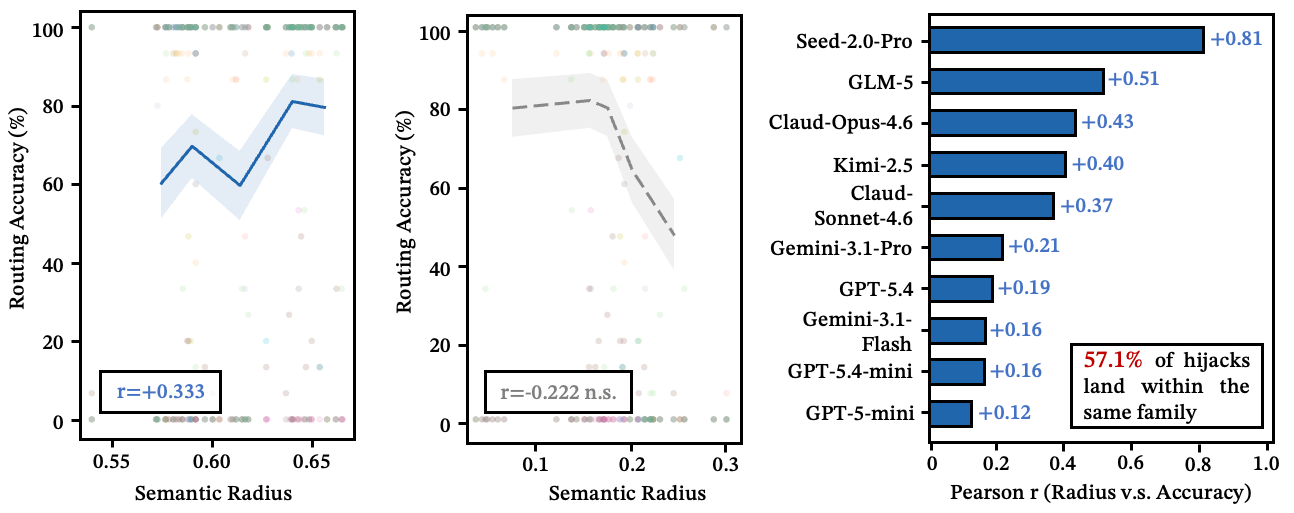
图 6:(左)更大的语义半径与更高的准确率相关;(中)族内清晰度无显著效果;(右)各模型相关性——所有 11 个模型均显示正相关。
路由失败时,失败方式是可预测的
路由有硬性天花板。但关键在于——当它崩溃时,错误不是噪声,而是结构化的。
94% 的错误停留在正确的邻域内
在 989 个真实技能中,绝大多数路由失败都落在目标技能的功能簇内。模型几乎总能找到正确的领域——Git、测试、数据库、文件处理——但在该领域内选错了具体技能。这不是全局混淆,而是局部竞争。
一个需要 git_rebase 的任务被路由到 git_merge。一个需要 run_pytest 的任务落到了 run_unittest。系统找到了正确的书架,但拿错了书。
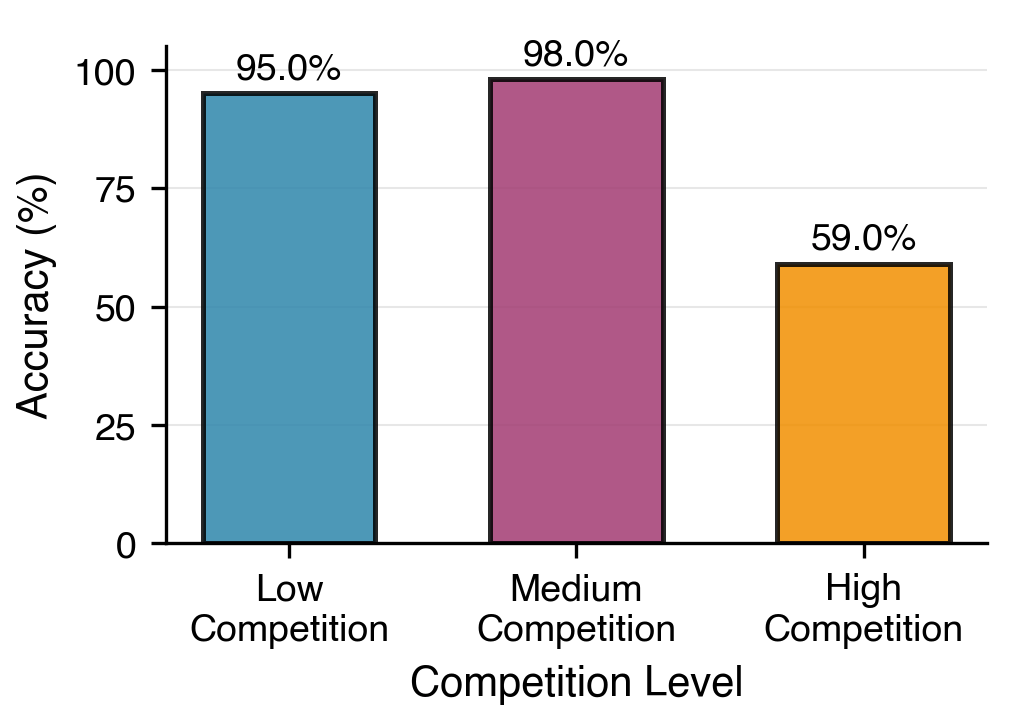
图 7:语义竞争对准确率的影响。低竞争:BGE 余弦相似度 <0.2;中竞争:0.2–0.5;高竞争:>0.5。
另见:族内错误分布、转移矩阵
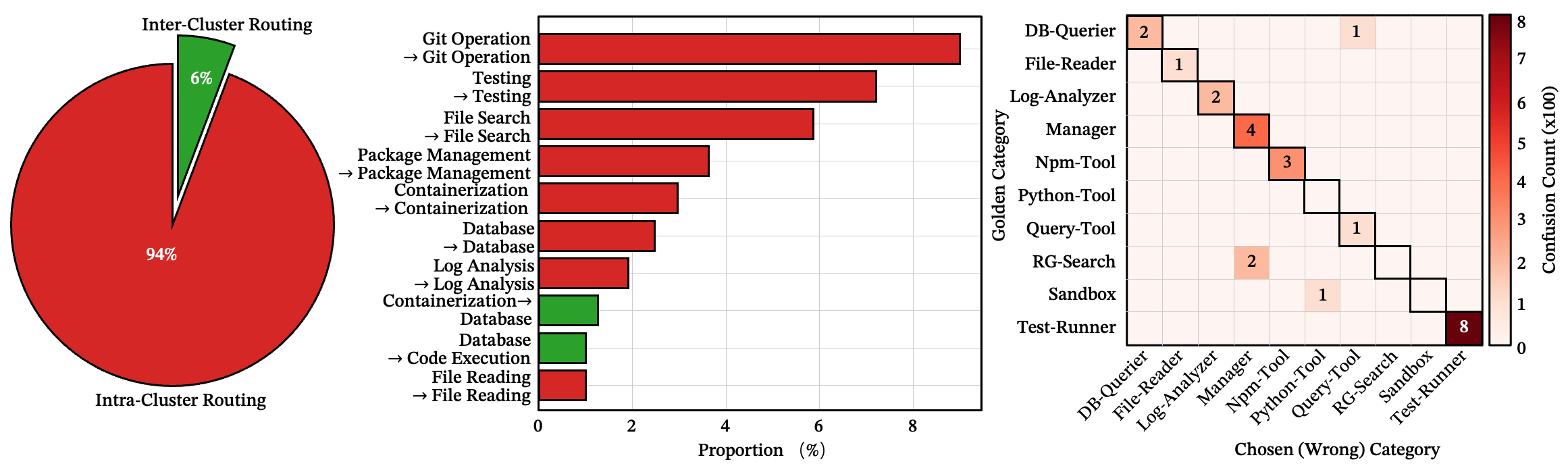
图 8:(a-b) 路由错误是否跨越功能族。94% 停留在同一族内。(c) 路由错误的转移矩阵。强烈的块对角结构证实了簇间隔离。块外的稀疏亮点表示罕见的跨簇混淆。
危险区:相似度 0.55 到 0.75 之间
这里有一个反直觉的发现。风险并不随相似度单调递增。近乎相同的技能(余弦 > 0.75)实际上危险性较低——模型将它们识别为近似重复。不相似的技能(< 0.55)很容易被排除。
最危险的区域是中高相似度区间 [0.55, 0.75)。这些竞争者足够相似以至于看起来合理,但又足够不同以至于模型无法可靠地区分它们。它们是技能路由的"恐怖谷"。
我们还观察到一个反直觉的搜索深度效应:将候选池从 Top-20 扩展到 Top-50 实际上增加了错误率,因为额外的候选者恰好落在这个危险区间内。
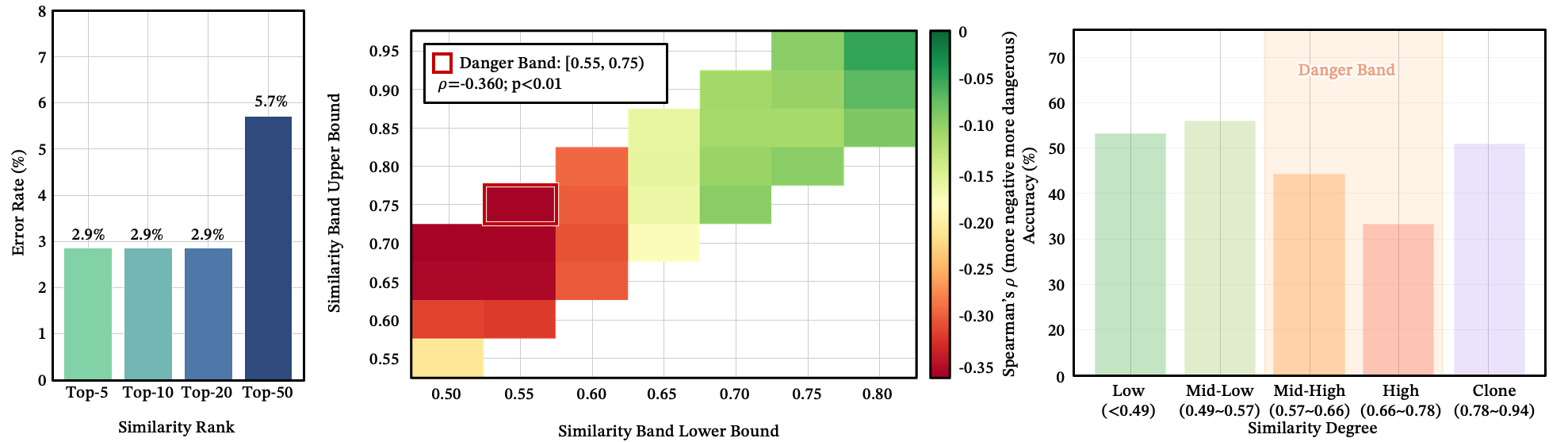
图 9:(a) 按相似度排名的错误率——Top-50 比 Top-20/10 引入更多错误。(b) 危险竞争区间的热力图——[0.55, 0.75) 显示最高的 Spearman 。(c) 各竞争区间的相似度响应曲线。
注意:失败峰值在中等相似度区间,而非最大相似度处。
实践意义: 在添加新技能之前,计算它与现有技能的余弦相似度。如果任何邻居落在 [0.55, 0.75) 区间,要么合并两者,要么重写两者的描述直到它们的相似度降至 0.55 以下。先扩展广度(新功能领域),再增加深度(拥挤领域中的更多技能)。对于多步流水线,在中间步骤重新注入原始用户意图以加固最薄弱的环节。
玻尔兹曼竞争指数
一个技能不与整个库竞争——只与其最近邻竞争。我们用玻尔兹曼风格的竞争指数来捕捉这一点:
其中 是目标技能的内在优势, 是来自周围竞争者的局部压力。结果表明,路由失败更多地由局部拥堵而非规模本身来解释。
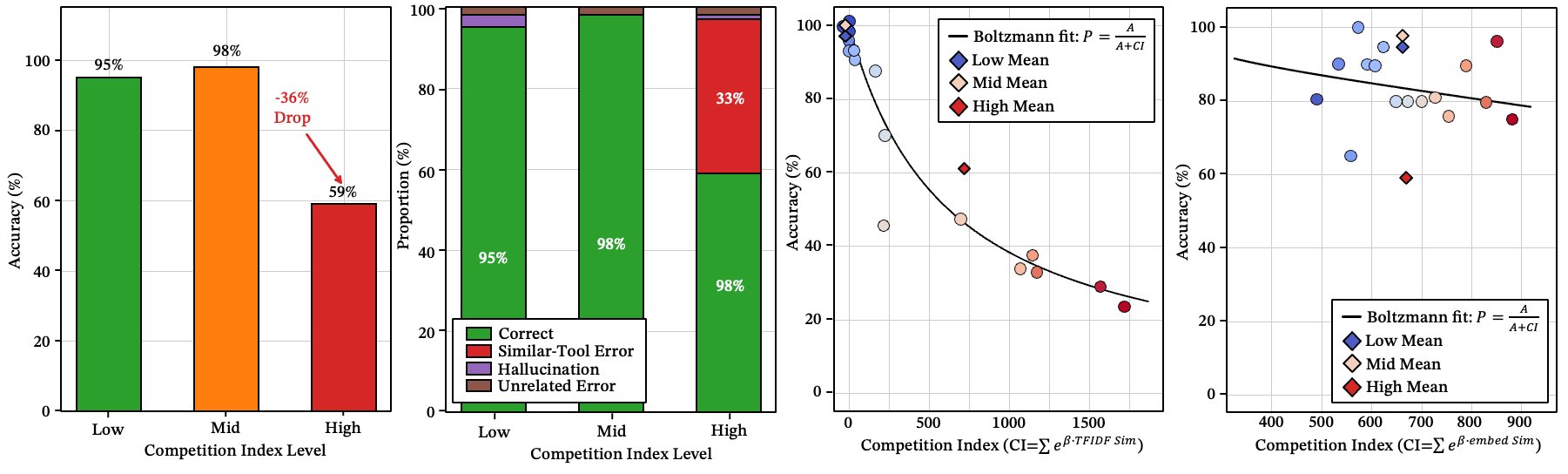
图 10:(a) 不同竞争指数水平的准确率;(b) 不同竞争指数水平的错误类型分布;(c-d) 竞争指数的玻尔兹曼拟合。
三种几何混淆模式
即使在单个簇内,错误也遵循由描述措辞塑造的方向性模式:
- 正向主导:技能 A 的更宽泛描述吸收了 B 的流量,但反之不然。
- 对称干扰:两个技能双向竞争——路由器来回摇摆。
- 反向主导:B 吸收 A,与直觉相反。
关键发现:对称干扰下的准确率(8.3%)远低于任一主导模式(约 33.5%)。而且这种结构由描述措辞决定,而非技能功能——改变几个关键词就能将对称干扰转化为单向主导。
另见:失败几何分析
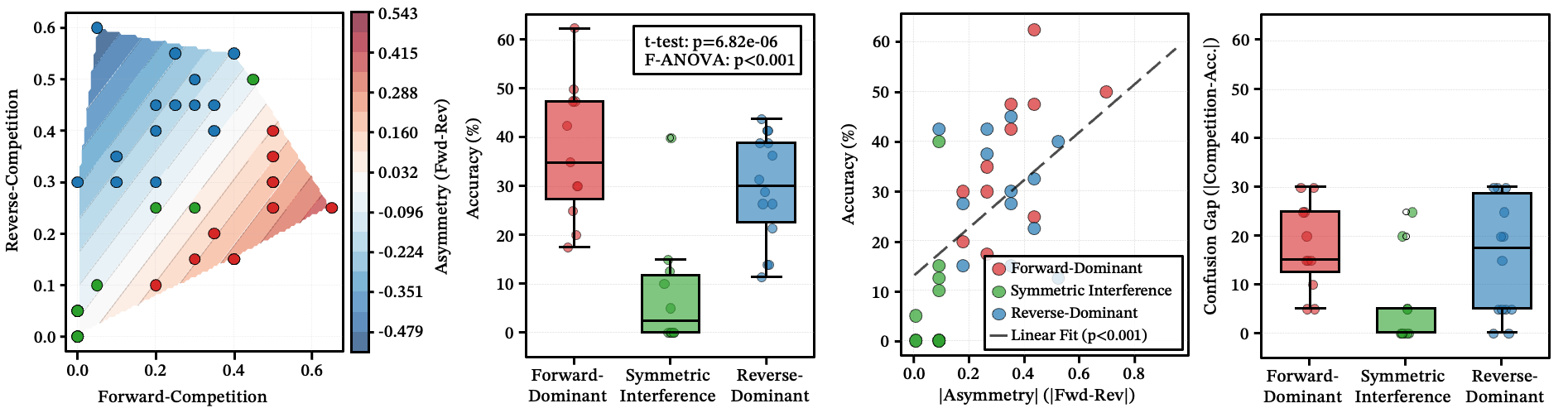
图 11:(a) 不对称密度场——红色 = 正向主导,蓝色 = 反向主导,白色 = 对称。(b) 各几何类型的准确率。(c) 不对称幅度预测准确率。(d) 对称干扰的混淆差距最大。
回弹效应:准确率在流水线步骤中呈 U 形变化
路由准确率在多步链中并非均匀分布,而是呈 U 形。
你可能预期准确率会随链长单调衰减。事实并非如此。在 时,第一步的准确率约为 65%,中间步骤降至 34%,最后一步恢复到约 65%。
机制如下:第一步受益于原始用户意图——提示词新鲜且具体。最后一步受益于强终端约束——模型知道它需要收敛并交付结果。中间步骤是脆弱的瓶颈,它们在压缩的中间状态上运行,原始目标已经淡化,模型漂移进入探索性领域。
启示:不要仅通过观察第一步和最后一步来评估技能链。中间才是崩溃发生的地方。
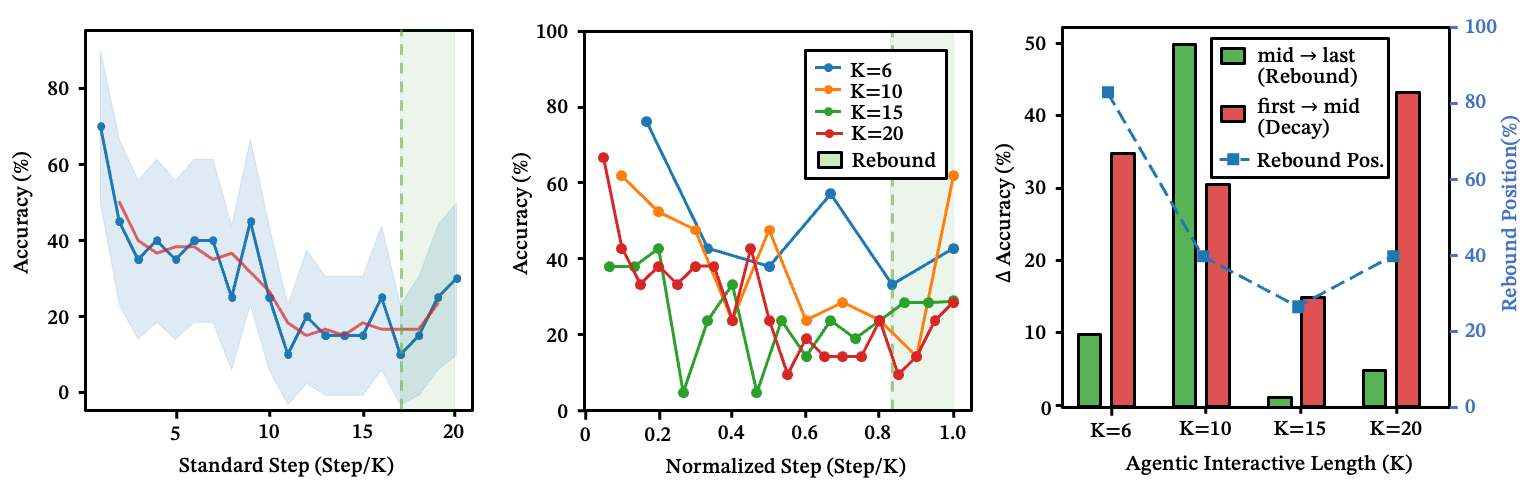
图 12:技能路由在流水线各步骤中的回弹现象。
黑洞效应:当语义锚点消失时会发生什么
以上所有内容都假设用户提示包含清晰的操作锚点——"rebase 到 main"、"运行 pytest 并生成覆盖率报告"。当这些锚点被移除时会怎样?
从 98% 到 18%:锚点移除实验
我们在相同任务上测试了两种条件:具体提示 vs. 模糊改写。结果触目惊心。
在具体提示下,即使在大规模下路由仍然强劲:
| 库规模 | 准确率 | 劫持率 | 幻觉率 |
|---|---|---|---|
| N=100 | 98.3% | 1.7% | 0% |
| N=150 | 99.2% | 0.8% | 0% |
| N=200 | 95.8% | 4.2% | 0% |
在相同任务的模糊改写下,系统崩溃:
| 库规模 | 准确率 | 劫持率 | 幻觉率 |
|---|---|---|---|
| N=100 | 33.3% | 66.7% | 0% |
| N=150 | 20.0% | 79.2% | 0% |
| N=200 | 18.3% | 81.7% | 0% |
注意:两种条件下幻觉率均为 0%。模型从不凭空捏造不存在的工具。相反,它从现有库中选择看起来合理的替代品。主导失败模式是劫持,而非幻觉。而且退化跨越了簇边界——我们观察到 sql → data、git → memory、data → memory 等漂移模式——一旦操作细节被剥离,模型会退回到在更抽象层面满足用户意图的技能。
语义黑洞:不在我们预期的位置
我们最初试图从嵌入空间的几何结构中寻找"黑洞"——那些结构位置应该吸引不成比例流量的技能。但这行不通:结构指标与观察到的劫持率不相关。
于是我们换了一个问题。我们设计了三个抽象程度递增的"万能技能",并测试它们的劫持能力。
发现:在具体提示下,每个万能技能的劫持率都是 0%。无论技能描述多么抽象或包罗万象,提示中清晰的操作意图都会让它对路由器"隐形"。
黑洞只在两个条件同时满足时才会激活:
- 技能本身高度抽象(过度泛化的容器)
- 用户提示高度模糊(无操作锚点)
需要明确的是:黑洞不是幻觉出的工具——它们是库中已存在的过度泛化技能,在意图模糊时吸收流量。
在这种双重触发条件下,劫持率上升到 25-35%,并随库规模增长。
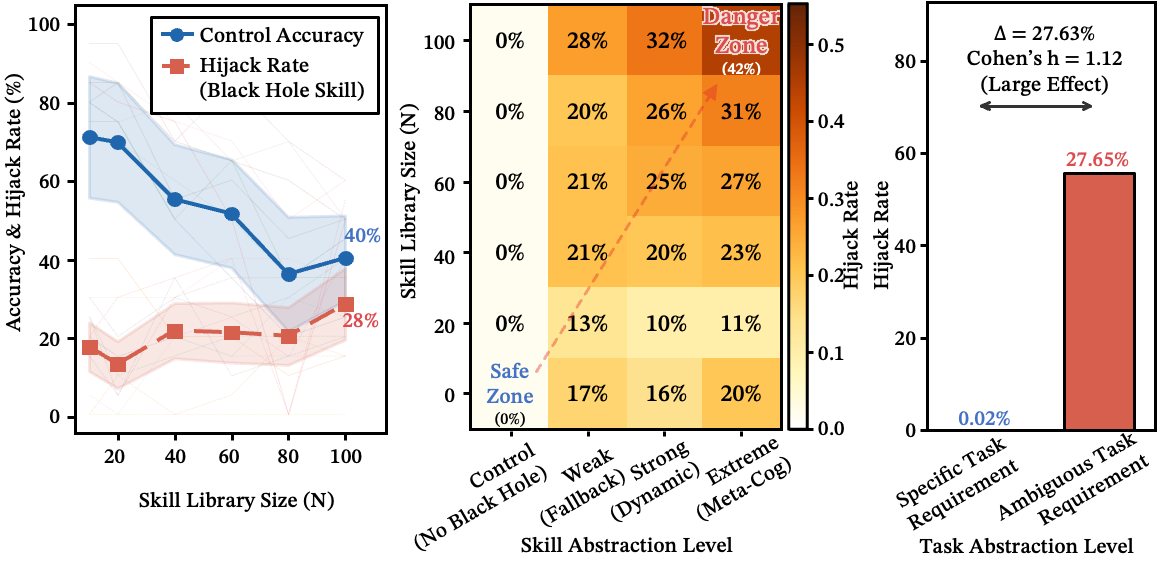
图 13:双重触发机制。(a) 随着库规模 增长,控制准确率(蓝色)衰减而抽象"万能工具"的劫持率(红色)上升;两线在 附近交叉,标志着系统性劫持的开始。(b) 劫持率关于技能抽象程度和库规模的相图——劫持集中在右上角(高抽象 + 大 ),证实单一条件不足以触发。(c) 任务具体性提供完全免疫:具体提示无论技能抽象程度如何,劫持率均为 0%,而模糊提示达到 28%。
注意:黑洞效应需要抽象技能和模糊提示同时存在——任一条件单独存在都是无害的(在创建Skill和发布任务时,至少有一刻你是清醒的)。
另见:黑洞随库规模的涌现
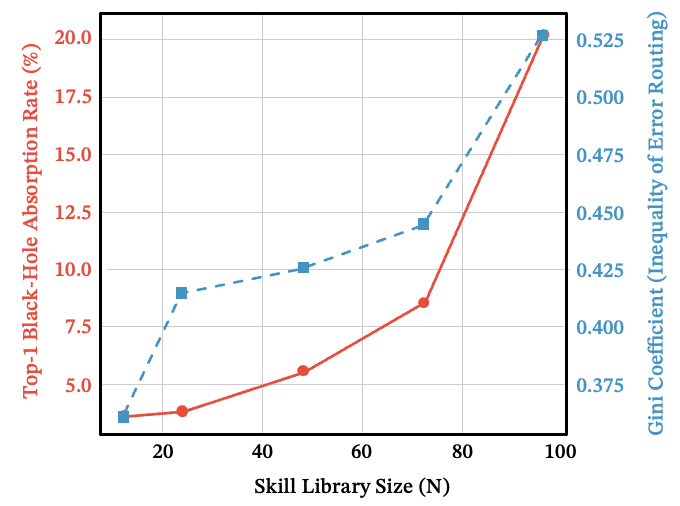
图 14:随着 增长,Top-1 黑洞吸收率和路由错误的基尼系数同步上升——错误集中到少数吸引子技能上。
完整的失败级联
随着锚点退化,路由失败通过不同的阶段逐步升级:
局部竞争 → 族内混淆 → 跨簇漂移 → 黑洞捕获
每个阶段都比上一个更严重,但每个阶段都需要更特定的条件才能触发。在早期阻断级联,后续的失败模式就永远不会出现。
实践意义: 将抽象的"万能技能"从扁平路由池中彻底移除。如果需要意图消歧,将其实现为专门的预路由阶段,而非一个竞争性技能。所有实验中最重要的单一变量是提示具体性——具体的操作锚点是控制整个失败级联的总开关。
执行悖论:路由与执行遵循不同的物理学
到目前为止,一切都是关于选择正确的技能。但选择和执行实际上遵循根本不同的规律。
无执行的路由是无记忆的
路由在执行注入状态之前看起来是无记忆的。两个技能是否被正确路由在本质上是独立的——。逻辑连贯的任务描述不会带来协同路由加成。每个决策都是孤立做出的。
另见:独立性分布图
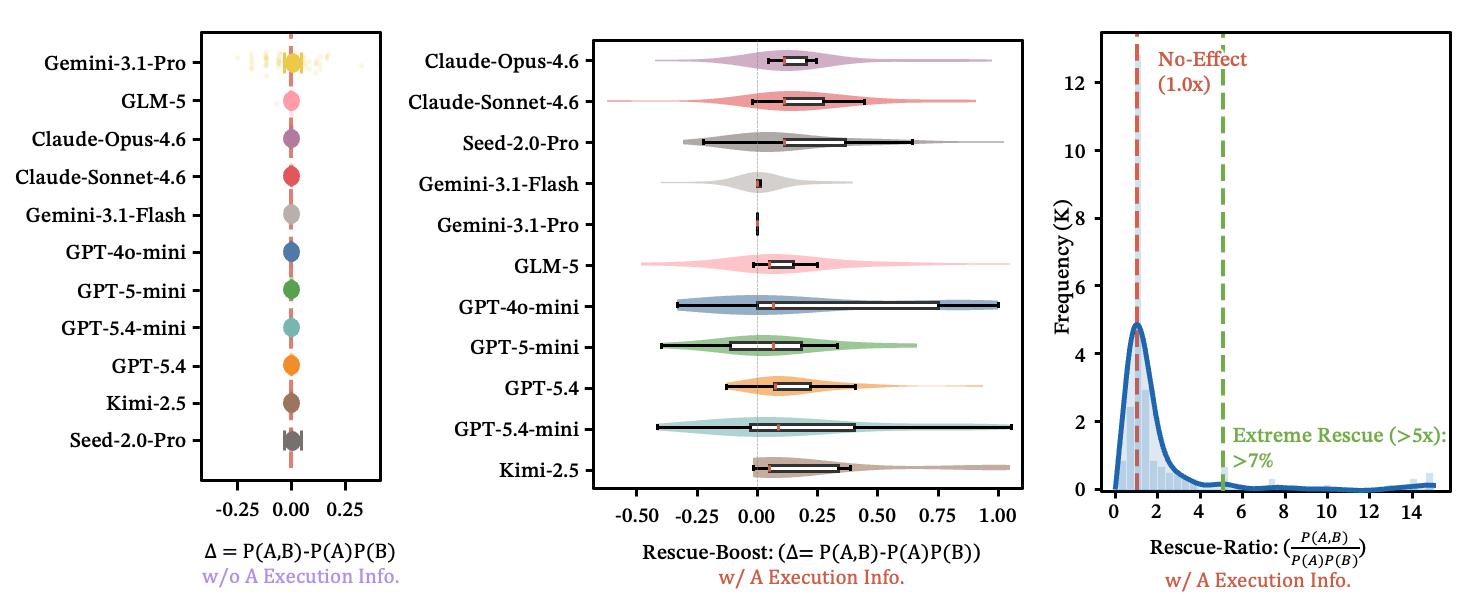
图 15:(a) 无执行时,每行是一个模型;水平线段是 的 95% 置信区间。几乎全部包含零。(b) 有执行时,不同 LLM 一致提供正向救援加成。(c) 超过 7% 的样本准确率提升 5 倍以上。
成功的执行能拯救路由错误
一旦上游执行成功,局面彻底改变。那些独立路由几乎不可能成功的步骤()在上游完成后跃升至 50–90% 的成功率。中位救援因子约为 4 倍。
直觉是:成功的执行将模糊的搜索空间压缩为具体的、有锚点的问题。这不是更好的规划——而是状态具体化。步骤 B 本身越难,救援效果越强:
这与我们所有发现形成闭环:操作锚点是贯穿整个系统的主变量。在路由阶段,它们来自描述和提示。在执行阶段,它们来自上游步骤产生的具体状态。
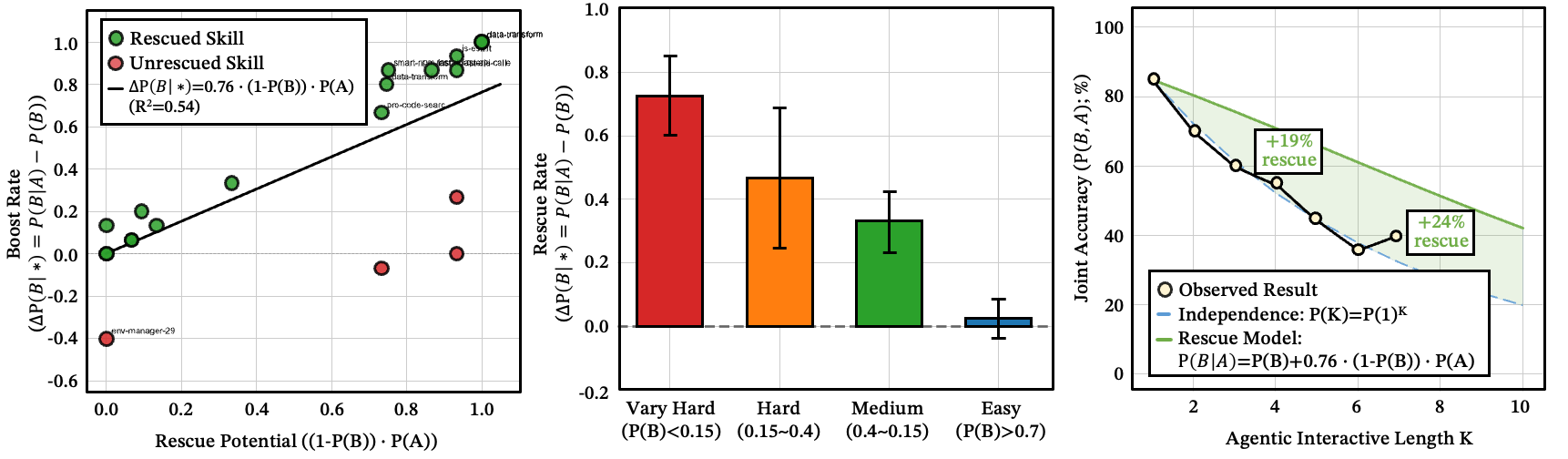
图 16:(a) 技能 A 和 B 的独立概率分布;(b) 1,200 个数据点的 vs. ——大多数位于对角线上方;(c) 救援比率分布,中位数约 4.09 倍;(d) 救援公式的经验验证;(e) 救援集中在困难问题上;(f) 各模型的小提琴图。
注意:执行改变了状态,因此下游选择不再独立——救援效应在最难的问题上最强。
错误传播取决于耦合度,而非链长
当上游步骤出错时,是否会毒害下游所有步骤?这取决于步骤间的耦合度,而非链长。
- 紧密数据依赖:下游性能下降约 22%。
- 松散依赖:系统自愈——下游步骤识别出有缺陷的输入并丢弃它,恢复约 10%。
- 完全独立:下游基本不受影响。
另见:依赖类型效应、忽略率机制
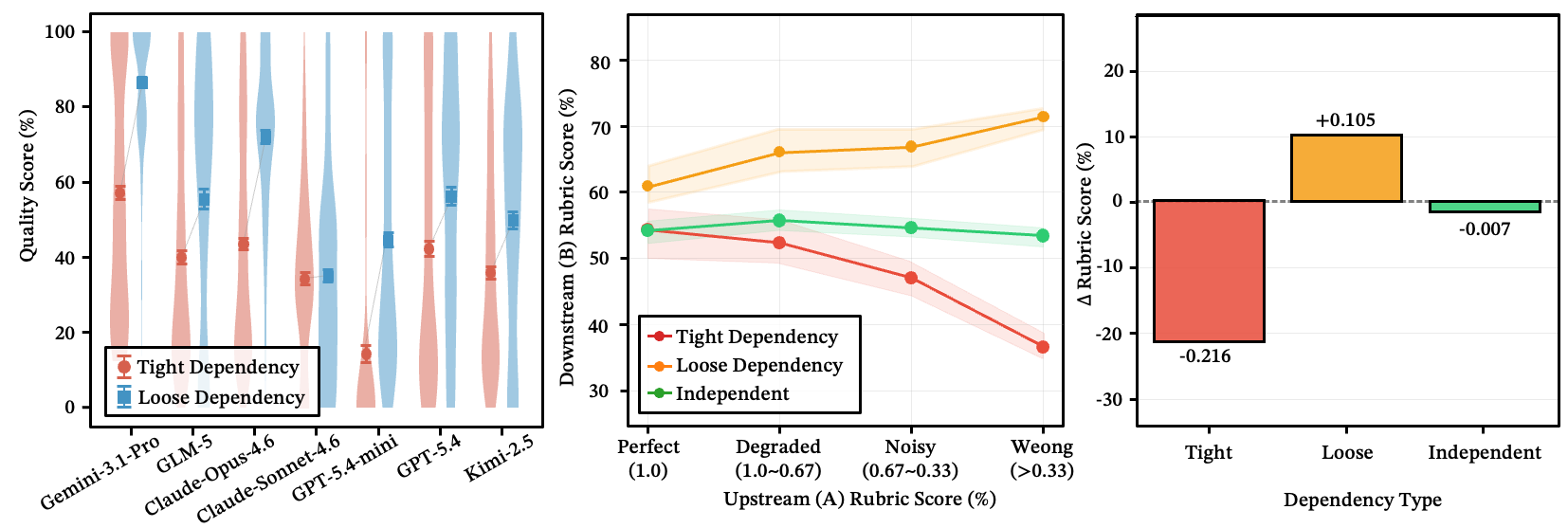
图 17:错误传播:(a-b) 紧密依赖导致陡峭的质量退化,松散依赖实现自愈,独立则平坦;(c) 各类型的总分下降——紧密:−0.216,松散:+0.105(自愈),独立:−0.007。
强拖 vs. 弱拽:两种执行体制
当两个技能联合执行时,一个变量占主导地位:它们之间的能力差距。
- 强拖(大差距):强技能为弱技能搭建脚手架。平均协同效应:+0.265。
- 弱拽(小差距,独立任务):同级技能争夺注意力和输出空间。平均协同效应:-0.115——大多数表现比任一技能单独执行更差。
如果两个任务都很难且相互独立,请顺序执行——不要强行将它们塞入同一次生成中。
另见:执行体制边界
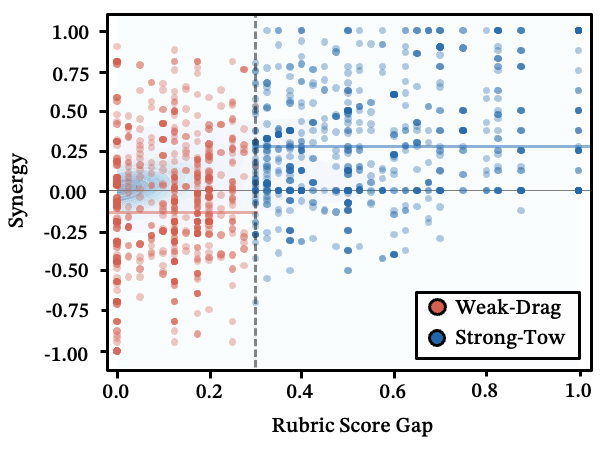
图 18:能力差距 vs. 协同分数——强拖与弱拽之间的边界。
实践意义: 将路由和执行视为独立的优化目标——改善一个并不会改善另一个。在困难的下游步骤之前放置一个简单的高成功率步骤,以利用救援效应。优先选择步骤间的松散耦合,使系统能够自愈。将强技能与弱技能配对——永远不要弱与弱配对。
总结
Agent 技能库不是被动的注册表。它们是由一小组可复现定律支配的竞争性语义生态系统。失败遵循一个级联——对数衰减、局部竞争、簇内混淆、锚点丢失、黑洞捕获——每个阶段都需要比上一个更特定的条件。在早期阻断级联,后续的失败模式就永远不会出现。
扩展 Agent 能力不是一个可以蛮力解决的工程问题。它是一个具有相变和临界阈值的物理问题。理解这些动力学,是一个能优雅处理 500 个技能的 Agent 与一个在 50 个技能时就崩溃的 Agent 之间的区别。
我们正在发布完整的数据集和评估框架,以帮助社区构建可扩展的 Agent 系统——不仅在它们提供的技能数量上扩展,更在它们使用这些技能的可靠性上扩展。
核心要点
- 对数墙是真实存在的。 技能库每翻一倍就会带来固定的准确率损失——而且在流水线步骤中复合累积。在 时,三步任务实际上已经失效。
- 竞争是局部的,而非全局的。 一个技能不与整个库竞争——只与其语义邻居竞争。[0.55, 0.75) 余弦相似度区间是路由的死亡地带。
- 抽象的"万能工具"是黑洞。 它们只在模糊提示下激活,但一旦激活,就会劫持 20-35% 的所有路由。解决方案是架构性的:将它们从扁平注册表中移除。
- 执行拯救路由——但反之不然。 成功的上游步骤将下游准确率提升约 4 倍。设计流水线时,将容易成功的步骤放在前面。