
BenchRouter: 基于容器化基准路由的零适配 LLM 评测


![]()
BenchRouter 是一个轻量级的评测即服务(EaaS)平台,它将 LLM 评测请求路由到容器化的 benchmark 环境中,适配成本为零。Benchmark 作者不需要编写框架插件或适配庞大的评测工具包,BenchRouter 将每个 benchmark 视为一个不透明的容器——读取 4 个环境变量,写入 1 个 JSON 文件。平台目前统一了 6 大评测领域的 8 个 benchmark,从 MCP 工具调用到真实软件工程任务,全部通过一条 benchrouter run 命令执行。新增一个 benchmark 的成本是两个 YAML 文件加一个脚本,而不是一次框架迁移。
动机
LLM 评测领域存在一个结构性问题:benchmark 不缺,但跑起来很贵。我们认为,这个差距不是 benchmark 数量不够,而是运行它们的适配成本太高。
我们识别出三种适配成本的来源:
适配成本 I —— 框架锁定。 大多数评测平台围绕插件或适配器体系组织。VLMEvalKit 要求作者在其框架内实现 Python 类;Harbor 要求按其注册表 API 编写适配器代码;AgentBench 硬编码了环境配置。每一种情况下,集成一个 benchmark 都意味着将评测逻辑改写以适配他人的抽象。对于已经有可运行评测代码的 benchmark 作者来说,这是纯粹的额外开销。
适配成本 II —— 统一接口导致的改写风险。 现有框架追求"统一接口":所有 benchmark 必须适配同一套 API 调用、环境初始化和结果上报方式。这对 agentic benchmark 的伤害尤其大。Agent 评测的核心流程往往与环境深度耦合——MCPMark 需要在真实 PostgreSQL 和 Playwright 上多轮交互,SWE-bench Pro 需要在隔离的 Docker daemon 中生成和执行补丁,WebArena 需要在完整的 Magento 实例上进行端到端操作。将这些流程改写为框架统一接口,不仅工程量巨大,更关键的是容易引入评分偏差:改写后的 harness 可能无法完全复现原始 benchmark 的环境条件和评分逻辑,导致所得分数与官方结果不可比。BenchRouter 选择不改写:原始 benchmark 代码原样运行,平台只负责路由和环境编排。
适配成本 III —— 上游同步困难。 统一接口还带来一个持续性问题:benchmark 的上游仓库一旦更新(修 bug、改评分标准、新增 task),下游的适配代码也必须跟着改,否则评测结果就脱离了社区基线。维护者需要持续追踪上游变更并同步适配层,这是一个不断累积的运维负担。BenchRouter 的设计从根源上避免了这个问题——桥接脚本只翻译环境变量,不修改评测逻辑。上游更新时,只需 rebuild Docker 镜像即可拉取最新代码,桥接层通常不需要任何改动。
下表总结了 BenchRouter 与现有评测框架在这三个维度上的对比:
| 框架 | 集成方式 | 原始代码改写量 | 上游更新适配 |
|---|---|---|---|
| VLMEvalKit | 修改框架 Python 代码 | 大量(需适配统一接口) | 需同步适配层 |
| Harbor | 编写适配器类 | 中等 | 需同步适配器 |
| AgentBench | 硬编码配置 | 大量(硬编码环境) | 需重写配置 |
| BenchRouter | 2 YAML 文件 + 1 脚本 | 零(原始代码原样运行) | rebuild 镜像即可 |
BenchRouter 同时解决了这三种成本:最小契约协议消除框架锁定,不改写原始评测代码避免评分偏差,桥接脚本只翻译环境变量使上游同步几乎零成本。
设计总览
下图展示了 BenchRouter 的端到端设计——从顶部的模型 API,经过路由核心层,到底部的两种容器化执行模式,左侧是最小契约,右侧是标准化输出。
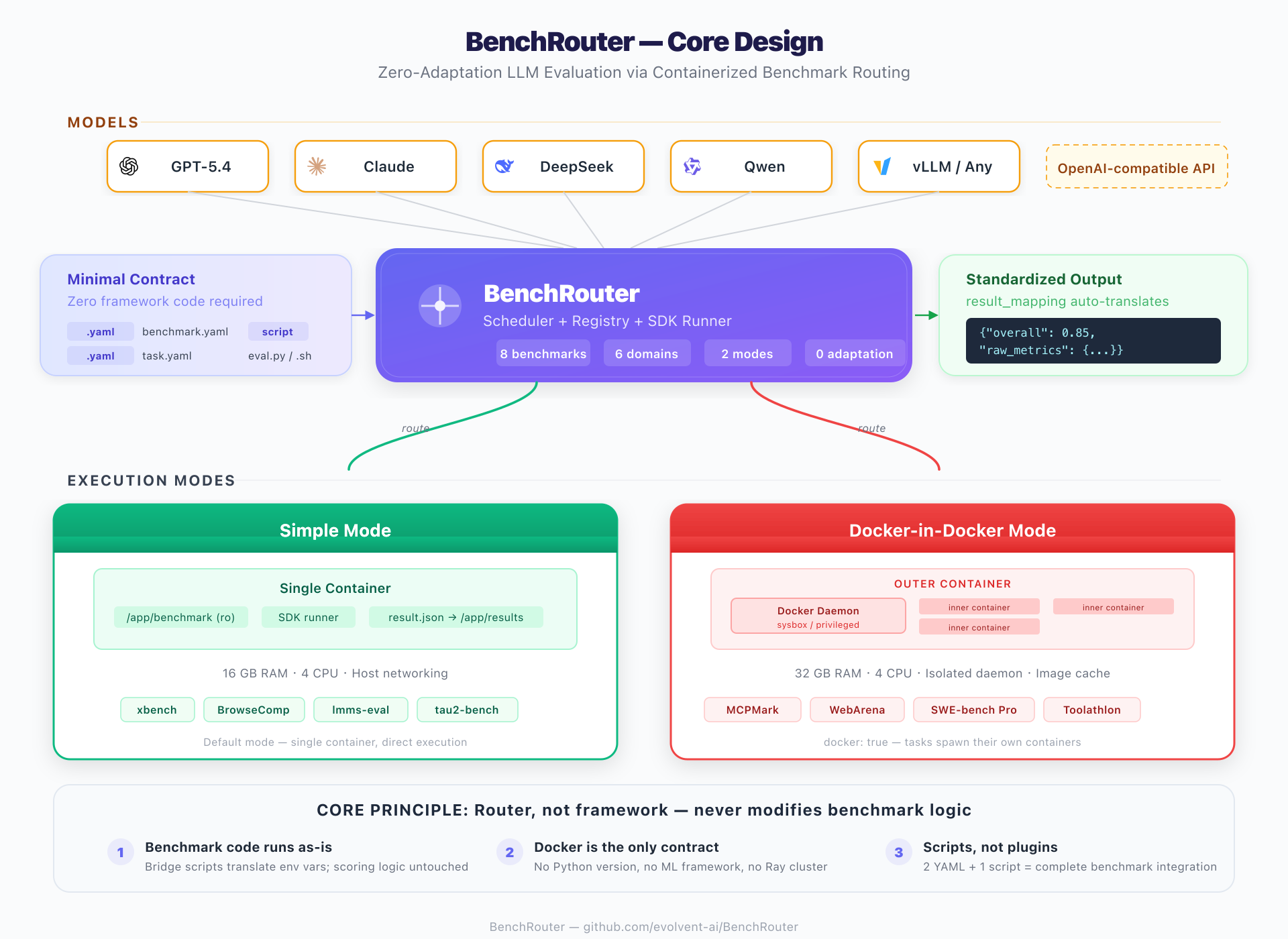 核心原则很简单:BenchRouter 是路由器,不是框架——它从不修改原始 benchmark 的逻辑。 这正是接入成本和长期维护成本都低的根本原因。四条设计选择共同保障了这一原则:
核心原则很简单:BenchRouter 是路由器,不是框架——它从不修改原始 benchmark 的逻辑。 这正是接入成本和长期维护成本都低的根本原因。四条设计选择共同保障了这一原则:
-
Benchmark 代码原样运行。 桥接脚本翻译环境变 量;打分逻辑从不修改。无论集成方式是 60 行的桥接脚本、一次带兼容补丁的 Python API 调用,还是 patch 官方代码中的一个函数,benchmark 的原始评测代码都原样运行。这正是 BenchRouter 避免评分偏差、消除上游同步负担的方式。
-
Docker 是唯一的运行时契约。 没有 Python 版本要求,没有 ML 框架依赖,不需要 Ray 集群。能在容器里跑的程序就能在 BenchRouter 上跑。这消除了困扰 benchmark 可复现性的"在我机器上能跑"问题,也意味着 benchmark 作者不需要重构代码来适配平台的环境模型。
-
模型是外部的。 BenchRouter 评测模型,不托管模型。模型运行在 OpenAI 兼容 API 后面(vLLM、OpenAI、Anthropic、DeepSeek 或任何代理)。这种解耦意味着你可以评测任何模型,无需修改评测平台。
-
脚本,不是插件。 新增 benchmark 的全部协议是 2 个 YAML 文件和 1 个脚本。无需继承基类,无需导入框架,无需注册插件。结合原则 1,集成成本只是一层薄翻译层,而不是一次改写。
架构
BenchRouter 是路由器,不是框架。任何能读取环境变量并写出 JSON 文件的程序都是合法的评测任务。系统分为四层:
用户层 (CLI)
└── benchrouter run <benchmark> --model <model>
│
API 层 (FastAPI)
└── POST /evals/submit → Run + N Jobs
│
核心层 (Scheduler + Registry)
└── EvalScheduler: Run/Job 层级结构,信号量并发控制
└── Registry: 基于文件的持久化(无数据库)
│
Docker 执行层
├── Simple 模式: 1 容器 / 1 任务(默认)
└── DinD 模式: docker: true → 每任务独立 Docker daemon
Run/Job 层级结构。 一次 benchmark 执行产生一个 Run,包含 N 个并行 Job(每个 task 一个)。Job 在可配置的并发上限内同时执行(默认 8 路)。失败的任务产生 PARTIAL 状态而非整个 Run 失败——部分结果仍然会被聚合和报告。
按需构建环境。 Benchmark 作者在目录中放一个 Dockerfile,BenchRouter 自动发现它,首次使用时构建镜像(per-environment 加锁防止竞态),后续运行直接使用缓存。无需手动 docker build,无需维护镜像仓库。
结果标准化。 每个容器内的 SDK runner 读取任务的 result_mapping 配置,将 benchmark 特定的字段名(如 pass@1、accuracy)翻译为标准的 {overall, raw_metrics} schema。跨模型对比只需一次 API 调用。
最小契约
将一个 benchmark 接入 BenchRouter 只需要三样东西:
1. benchmark.yaml —— 声明 benchmark 及其任务:
name: "my-benchmark"
tasks:
- name: "task-a"
environment: "my-env"
- name: "task-b"
environment: "my-env"
2. task.yaml —— 每个任务的配置:
name: "task-a"
command: "python eval.py"
timeout: 3600
result_mapping:
overall: "pass@1"
3. 一个评测脚本 —— 任何可执行程序。契约是 4 个环境变量输入,1 个 JSON 文件输出:
| 输入 | 来源 |
|---|---|
BENCHROUTER_MODEL_ENDPOINT | OpenAI 兼容 API 基址 |
BENCHROUTER_MODEL_NAME | 模型标识符 |
OPENAI_API_KEY | API 密钥 |
BENCHROUTER_OUTPUT_DIR | 写入 result.json 的目录 |
一个调用 curl 然后写 {"overall": 0.85} 的 shell 脚本就是一个合法的 benchmark 任务。无需继承基类,无需导入框架,无需注册插件。
对于需要启动自身服务(数据库、浏览器、Web 应用)的 benchmark,设置 docker: true 启用 DinD 模式。预缓存镜像列在 docker_images 中,内部 daemon 直接从 tar 归档加载,无需网络拉取:
name: "mcpmark-pg"
command: "python /app/benchmark/run_mcpmark.py"
timeout: 7200
docker: true
docker_images:
- "pgvector/pgvector:0.8.0-pg17-bookworm"
extra_env:
POSTGRES_HOST: "localhost"
POSTGRES_PORT: "5432"
BenchRouter 检测到 docker: true 后,为任务分配独立的 Docker daemon(Sysbox 或 privileged),预加载列出的镜像,任务完成后自动清理。
Benchmark 覆盖与执行模式
调度器根据 task.yaml 中的一个字段决定如何运行每个任务:docker。设置 docker: true 时,任务获得独立的 Docker daemon(DinD 模式);否则直接在容器内运行(Simple 模式)。下表汇总了全部 8 个内置 benchmark:
| Benchmark | 领域 | 模式 | 核心特征 |
|---|---|---|---|
| MCPMark | 工具调用 | DinD | Postgres + Playwright 在 DinD 内部启动 |
| Toolathlon | 工具调用 | DinD | 35+ MCP server,无需外部凭证 |
| WebArena | Web 交互 | DinD | 9.6GB Magento 镜像,SOTA 61.7% 完成率 |
| BrowseComp | Web 浏览 | Simple | OpenAI simple-evals 浏览器 benchmark |
| SWE-bench Pro | 软件工程 | DinD | 防数据污染,per-task Docker daemon |
| lmms-eval | 多模态 | Simple | 70+ 图像 + 30+ 视频 benchmark |
| tau2-bench | 客服 | Simple |
两种执行模式适配各 benchmark 的隔离需求:
- Simple —— 一个容器跑一个任务。Benchmark 目录以只读方式挂载在
/app/benchmark,结果写入/app/results。容器运行python -m benchrouter.sdk.runner,使用 host 网络。适用于任务本身不需要启动容器的场景。 - DinD —— 在
task.yaml中设置docker: true。每个任务通过 Sysbox 运行时(首选)或 privileged 模式获得独立的 Docker daemon。预缓存镜像从 tar 归档加载到内部 daemon 中,避免数 GB 的网络拉取。容器运行dind-entrypoint.sh,启动 daemon、加载镜像,然后调用 SDK runner。适用于 benchmark 需要在内部启动自己的容器(数据库、Web 服务器、per-instance Docker 镜像)的场景。
集成案例:MCPMark
MCPMark 在 MCP(Model Context Protocol)工具调用上评测 LLM Agent,覆盖四个任务:文件系统操作、PostgreSQL 查询、Playwright 浏览器控制和 WebArena 交互。需要外部服务(PostgreSQL、Playwright)的任务使用 DinD 模式——数据库或浏览器在任务自己的 Docker daemon 内部启动,通过 task.yaml 中的 docker: true 和 docker_images 配置。
将 MCPMark 集成到 BenchRouter 需要:
- 一个
benchmark.yaml声明 4 个任务及其各自的环境。 - 每个任务一个
task.yaml,指定docker: true并列出需要预加载的镜像(如pgvector/pgvector:0.8.0-pg17-bookworm)。连接参数通过extra_env传入。 - 每个任务一个 60 行的桥接脚本,读取
BENCHROUTER_MODEL_ENDPOINT和BENCHROUTER_MODEL_NAME,通过 LiteLLM 配置上游 MCPMark 客户端,运行评测,写入result.json。
MCPMark 的评测代码没有做任何修改。整个集成——四个任务,覆盖文件系统、PostgreSQL、Playwright 和 WebArena——用了一个下午。
集成案例:SWE-bench Pro
SWE-bench Pro 是 BenchRouter 中隔离需求最苛刻的 benchmark。它的 731 个任务中,每个都会生成一个包含特定 commit 的 Python 仓库的 Docker 镜像,应用 agent 的 patch,然后运行项目的测试套件。这意味着评测本身需要一个 Docker daemon。
BenchRouter 的 DinD 模式通过以下步骤处理:
- 检测宿主机是否有 Sysbox 运行时(优先,安全性更好),否则回退到 privileged 模式。
- 为 DinD 容器内的
/var/lib/docker挂载一个 per-task 目录,让每个任务拥有隔离的 Docker 存储。 - 从缓存的 tar 归档中预加载 SWE-bench 基础镜像(避免每个任务都做耗时数分钟的网络拉取)。
- 在内部启动 Docker daemon,使用 overlay2(不支持堆叠 overlay2 的内核上回退到 vfs)。
- 在 DinD 容器内运行 SWE-bench 评测 harness,拥有完整的 Docker 访问权限。
8 个任务分片并行运行,每个都有自己的 Docker daemon、32GB 内存分配和隔离存储。完成 8 个分片中 6 个的 Run 返回 PARTIAL 状态,并汇总已完成分片的分数。
未来方向
BenchRouter 的近期优先事项:
- 更多 MCP benchmark。 MCP-Universe(Salesforce,6 领域,GPT-5 仅得 43.7%)和 GAIA(466 个真实世界问题)是自然的下一步集成目标,MCP 生态的月度 SDK 下载量已超过 9,700 万次。
- 云原生扩展。 将 Docker 执行分布到多台主机,支持大规模评测。
- 持久化排行榜。 跨评测活动的跨模型对比,而非仅限单次 Run。
- RL 奖励集成。 将 BenchRouter 标准化的结果格式与强化学习流水线对接,让评测分数成为训练信号而非仅仅是报告。