
面向组织的群体自进化 Agent:Evolvent's self-evolving AI system
面向 auto-research 的初步结果:一个 agent 群体如何在五个开放任务上持续学习
下一代 AI 系统的关键,不只是让一个 agent 更强,而是让一群 agent 像一个组织一样积累经验、共享知识、持续进化。
过去一年,大家已经看到单个 coding agent、research agent、data agent 可以完成越来越复杂的任务。但如果我们把视角从"一个 agent 能不能解决这一次任务"移到"一个组织能不能在长期任务中越做越好",问题就会变得完全不同。
人类组织的智能从来不只存在于某个个体脑子里。它存在于病例、论文、代码库、复盘文档、实验记录、操作手册和团队默契中。一个医生的病例会帮助后来者,一个工程团队的事故复盘会改变整个研发流程,一个增长团队的投放经验会成为下一轮实验的起点。
Agent 也应该这样。
我们认为,自进化 agent 的真正形态,不是一个模型在一次上下文窗口里"临场变聪明",而是一个 agent 群体在长期运行中形成组织记忆:每一次尝试、失败、修复、突破,都会进入共享经验层,被后续 agent 读取、压缩、复用,并推动下一轮探索更快到达有效区域。
这就是 Evolvent 正在构建的方向:让 agent 从一次性工具,变成拥有复利记忆的智能组织。
从单体智能到群体智能
今天大多数 agent 系统仍然像"雇了一个聪明实习生":它可以完成任务,但任务结束后,经验很难自然沉淀。下一次再启动,agent 仍然要重新理解代码、重新踩坑、重新发现哪些方法有效。
真实组织不是这样运转的。组织会把经验变成可复用资产:流程、知识库、benchmark、榜单、最佳实践、失败案例、领域术语、决策原则。个体会学习,团队也会学习。个体能力决定一次任务的上限,组织学习能力决定长期复利。
所以我们把 evolve 分成两个层次:
| 层次 | 服务对象 | 沉淀内容 | 作用 |
|---|---|---|---|
| 个体 evolve | 单个 agent | skills、memories、logs、state,以及它自己解决问题的方式。 | 让 agent 从个人历史中学习,少走重复弯路。 |
| 群体 evolve | 整个 agent 群体 | 任务轨迹、best programs、leaderboard、notes、synthesis、跨 agent 经验总结。 | 把多条探索路径压缩成组织经验,让后续 agent 直接站在群体探索的结果上。 |
个体 evolve 让 agent 更熟练,群体 evolve 让组织更聪明。真正有价值的不是"某个 agent 偶然做对了一次",而是系统能不能把这次做对的原因留下来,让下一批 agent 更快、更稳、更系统地做对。
在实现上,这意味着 agent 不能只共享最终答案,还要共享探索过程:哪些方向试过、为什么失败、哪个程序当前最好、哪些策略跨任务稳定有效、哪些经验应该进入长期记忆。每个 agent 都在独立工作区里探索,由 grader 给出反馈;共享状态层持续保存 attempts、notes、skills、leaderboard;系统周期性触发 reflect、consolidate、pivot,把零散轨迹整理成可被下一轮 agent 使用的组织知识。
这不是简单地把 context window 变长,而是给 agent 群体加上一套"组织学习回路"。
为什么是 AutoResearch
为了验证这套机制,我们选择了一组 AutoResearch 风格任务。它们不是聊天问答,也不是固定流程自动化,而是需要反复尝试、评估、修正、再尝试的开放式搜索问题。
这类任务天然适合检验群体智能:
- 反馈足够可验证:每次提交都会被环境评分,而不是只靠主观判断。
- 搜索空间足够大:单个 agent 很难一次就稳定找到高质量路径。
- 经验可迁移:成功模式、失败模式、启发式和代码结构都可以被后续 agent 继承。
- 领域差异足够大:如果同一套机制能跨系统、算法、科学任务工作,说明它不是为单一 benchmark 定制的技巧。
我们用五个场景观察 Evolvent 的群体进化闭环:信号处理、底层 kernel 优化、MoE 负载均衡、组合优化和分子设计。它们覆盖了从数值科学、系统软件到 AI4Sci 的不同问题形态,但都可以被统一抽象成同一个循环:
agent 生成候选方案,环境给出评价,系统记录轨迹并沉淀群体经验,后续 agent 再基于这些经验继续搜索。
下面是五个任务从初始 seed 到 evolved best 的性能跨度:
org-evol · seed → best
任务性能跨度
五个 AutoResearch 任务上,evolved best 相对初始 seed 的提升。
| 环境 | 任务是什么 | agent 主要优化什么 | 观察到的 best |
|---|---|---|---|
| 信号处理 | 实时自适应信号滤波。 | 在降噪的同时保留动态变化,让输出更贴近 clean target。 | 0.7767,越高越好。 |
| Kernel Builder | 底层 VLIW / SIMD kernel 调度优化。 | 重排指令、向量化、调整内存访问与调度,让 cycles 更低。 | 2105 cycles,越低越好。 |
| ADRS / EPLB | MoE expert load balancing。 | 复制热点 expert,重新放置到 GPU,减少负载倾斜。 | 0.1450,越高越好。 |
| Frontier-CS / Polyominoes | 算法竞赛类 polyomino 拼图 / 装箱。 | 搜索摆放策略,提高装箱紧凑度和最终评分。 | 80.739,越高越好。 |
| Drug Design | 候选小分子生成与优化。 | 修改 scaffold、筛选候选结构,提高目标分数。 | 0.9741,越高越好。 |
下面是同一组实验在真实评测下的逐任务 best-so-far 记录——每个任务独立绘制,横轴是 grader 评分的尝试序号。可以看到,很多提升不是线性爬升,而是发生在若干次尝试之后的跃迁点,随后进入平台期:

案例 1:信号处理
信号处理是最容易直观看到"进化"发生的一组实验。任务是实时自适应信号滤波:输入是一条带噪的动态信号,目标是在降噪的同时尽量贴近干净的目标信号。
这个任务的难点在于平衡。滤波太弱,噪声留下来;滤波太强,动态细节被抹掉。agent 需要在大量候选程序中找到更稳的滤波策略,并通过评分反馈不断修正。
我们跑了两组 context pool 实验,一组使用 Qwen,一组使用 Claude。两组都能看到 best-so-far 随着尝试推进而提升,并且后续 turn 的起点更高。这意味着系统沉淀下来的经验已经开始影响新的探索,而不是每个 agent 都从零开始。
| 实验 | 结果 | 观察 |
|---|---|---|
| Qwen context pool | best = 0.7584,105 条有效记录。 | best-so-far 持续抬升,后期起点明显高于早期。 |
| Claude context pool | best = 0.7767,42 条有效记录。 | 在更少尝试数内达到更高 best,best 程序能产生更贴近目标信号的滤波曲线。 |
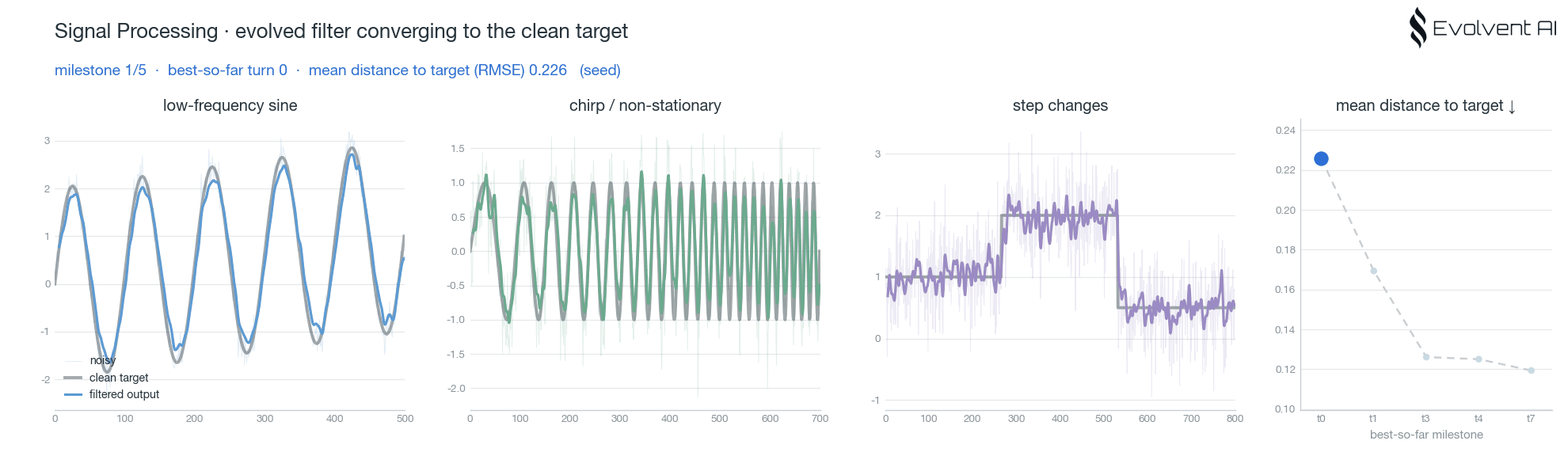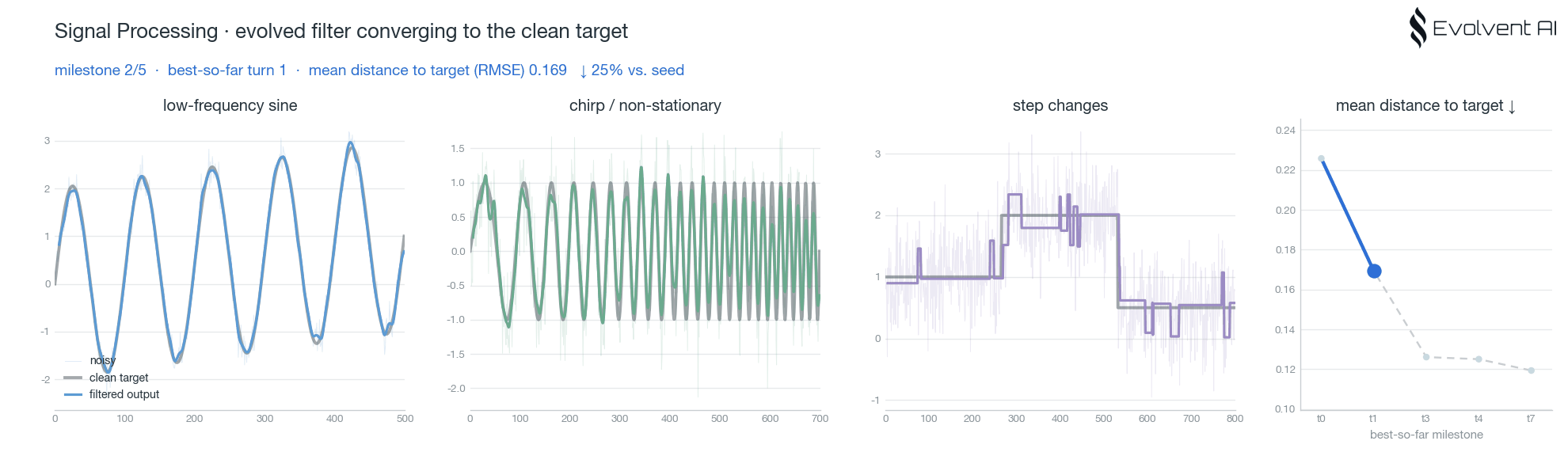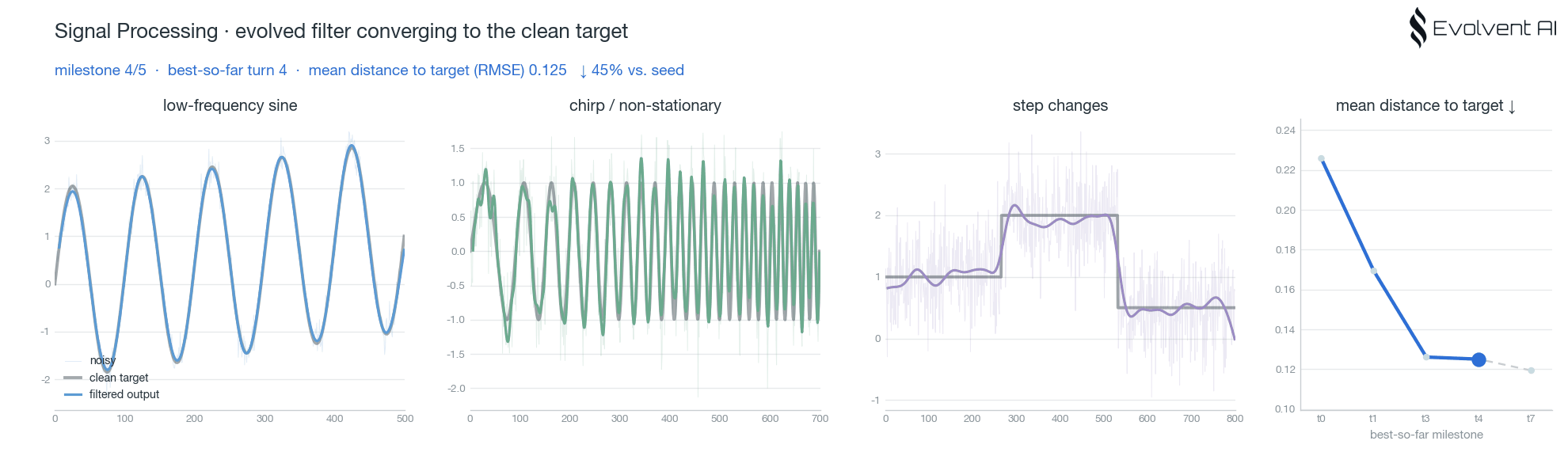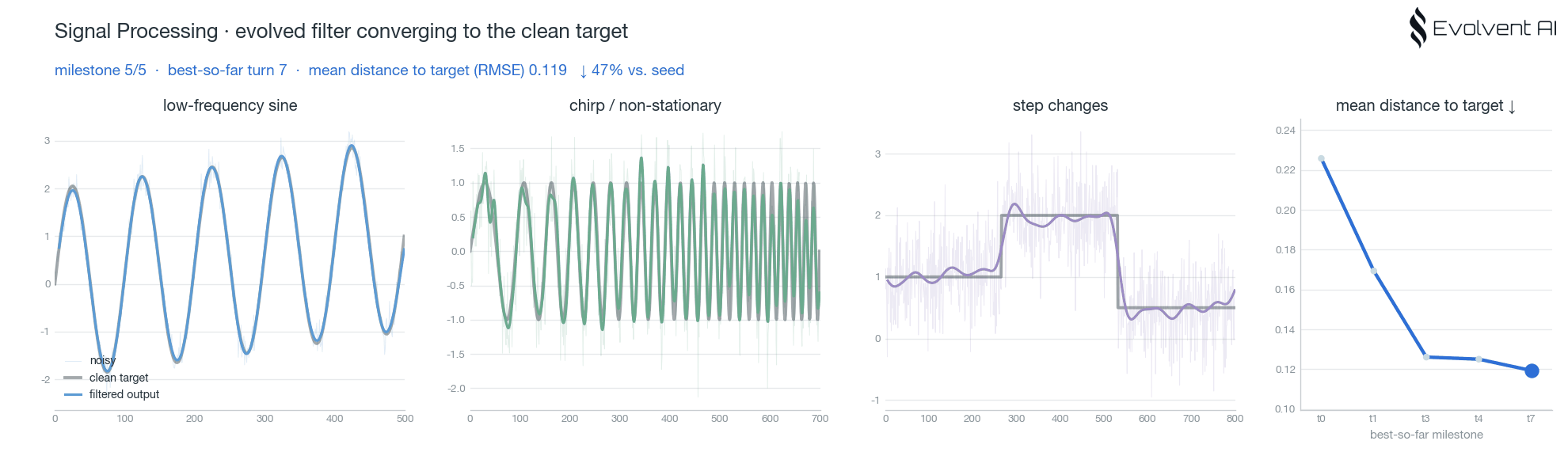
这里的核心不是"某个模型写出了一段不错的滤波代码",而是系统开始形成任务级直觉:哪些平滑策略会损失动态,哪些参数更稳,哪些结构值得继续局部搜索。这些直觉进入共享经验层后,后续 agent 的探索起点就被整体抬高了。
案例 2:底层 Kernel 优化
Kernel Builder 是一个偏底层系统的问题。环境给定一个 kernel,agent 需要通过调度、向量化和内存访问优化降低 cycles。这个任务的反馈非常工程化:一个看似很小的代码改动,可能会改变整个执行流水线。
这类问题很适合体现群体智能的价值。单个 agent 可能会试出一个局部优化,比如减少某类 load/store,或者调整 SIMD 调度。但如果这些发现只停留在一次运行里,下一次就会被浪费。群体 evolve 的意义,是把这些微小但昂贵的发现沉淀下来:哪些优化方向真的有效,哪些会引入调度冲突,哪些代码形态更容易被硬件执行模型接受。

当后续 agent 继承这些模式时,它不再是在随机变异代码,而是在已有工程经验上继续搜索。对系统软件和性能优化来说,这一点尤其重要,因为真正的进步往往来自大量小经验的累积,而不是一次"大灵感"。
案例 3:ADRS / EPLB
EPLB 是 MoE serving 里的 expert load balancing 问题。真实系统中,某些 expert 会成为热点,导致 GPU 负载不均、尾延迟上升。agent 的任务是决定哪些 expert 需要复制,如何放置到不同 GPU 上,从而让负载更均衡。
这个任务的关键在于全局权衡。只盯住局部热点,可能会把瓶颈迁移到另一个 GPU;只追求平均负载,也可能忽略真实 workload 中的长尾压力。单次尝试往往只能证明一个策略在某个 workload 上有效,而多次尝试叠加后,系统可以总结出更稳的策略:热点 expert 优先复制,不要只追局部均衡,关注跨 GPU 的瓶颈迁移。

这就是组织经验和单次结果的区别。单次结果告诉你"这次怎么放";组织经验告诉后续 agent"面对类似负载形态时,应该优先考虑什么"。
案例 4:Frontier-CS / Polyominoes
Polyominoes 是一个组合优化任务:给定一组不规则拼图块,agent 需要把它们尽量紧密地放进网格里。它不像数值优化那样有平滑梯度,更多依赖搜索策略、局部修复和约束处理。
这类任务里的经验通常不是一个单一公式,而是一组启发式:先放大块,减少孔洞,局部回退,把边界形状用于后续填充,避免早期选择造成不可修复的空隙。单个 agent 可以在自己的轨迹里形成这些技能,群体层面则把有效启发式写入共享 notes,帮助后续 agent 更快找到可行布局。

组合优化往往没有一个"看一眼就知道正确"的答案。它需要耐心、试错和记忆。群体智能的价值,就是让试错不被浪费。
案例 5:Drug Design
Drug Design 是一个 AI4Sci 风格的分子优化任务。agent 需要在候选分子空间中搜索更高分的结构,同时兼顾有效性、相似性、新颖性等约束。
这个任务很有代表性,因为它不是简单让分数随机上升。随着 evolve 推进,候选会逐渐偏向某些更稳定的 scaffold family。也就是说,系统记录的不只是"哪个分子得分高",还包括"哪些结构改动方向更可能带来高分"。

对 AI4Sci 来说,这一点很关键。真正有用的系统不应该只是吐出一个分数最高的候选,而应该帮助研究者理解搜索过程:哪些方向被探索过,哪些结构族更有希望,哪些约束在限制进一步提升。群体经验让这些信息不再散落在一次次尝试里,而是被整理成下一轮研究可以复用的知识。
群体智能的飞轮
把这些案例放在一起看,我们真正想证明的不是"某个环境里拿到了一个不错分数",而是一个更底层的闭环开始成立:
- agent 并行探索不同候选方案。
- 环境和 grader 给出可比较的反馈。
- 系统保存完整轨迹、best programs、失败案例和中间观察。
- 经验被整理成 notes、skills、synthesis 和 leaderboard。
- 后续 agent 读取这些经验,用更高的起点继续搜索。
这个循环每转一轮,组织就多一点经验;经验越多,下一轮探索越少浪费;探索越有效,系统越能发现新的可复用模式。最终形成的不是一个"会做某件事的 agent",而是一个会持续学习的 agent 组织。
我们相信,这会成为 B 端 agent 系统的重要形态。企业真正需要的不是一次性 demo,而是长期运行后越来越懂业务、越来越懂系统、越来越懂组织偏好的智能体网络。投流、增长运营、行业研究、研发流程自动化、数据分析、实验设计,都是同一类问题:任务会重复出现,环境会变化,经验必须沉淀,组织需要越跑越强。
Evolvent 的目标,就是把这种长期复利带到 agent 系统里。
不是让一个 agent 单次表现得更像专家,而是让一群 agent 在持续工作中,逐渐形成一个真正会学习、会协作、会进化的智能组织。