
如何在大模型生成前预测推理任务的准确性?
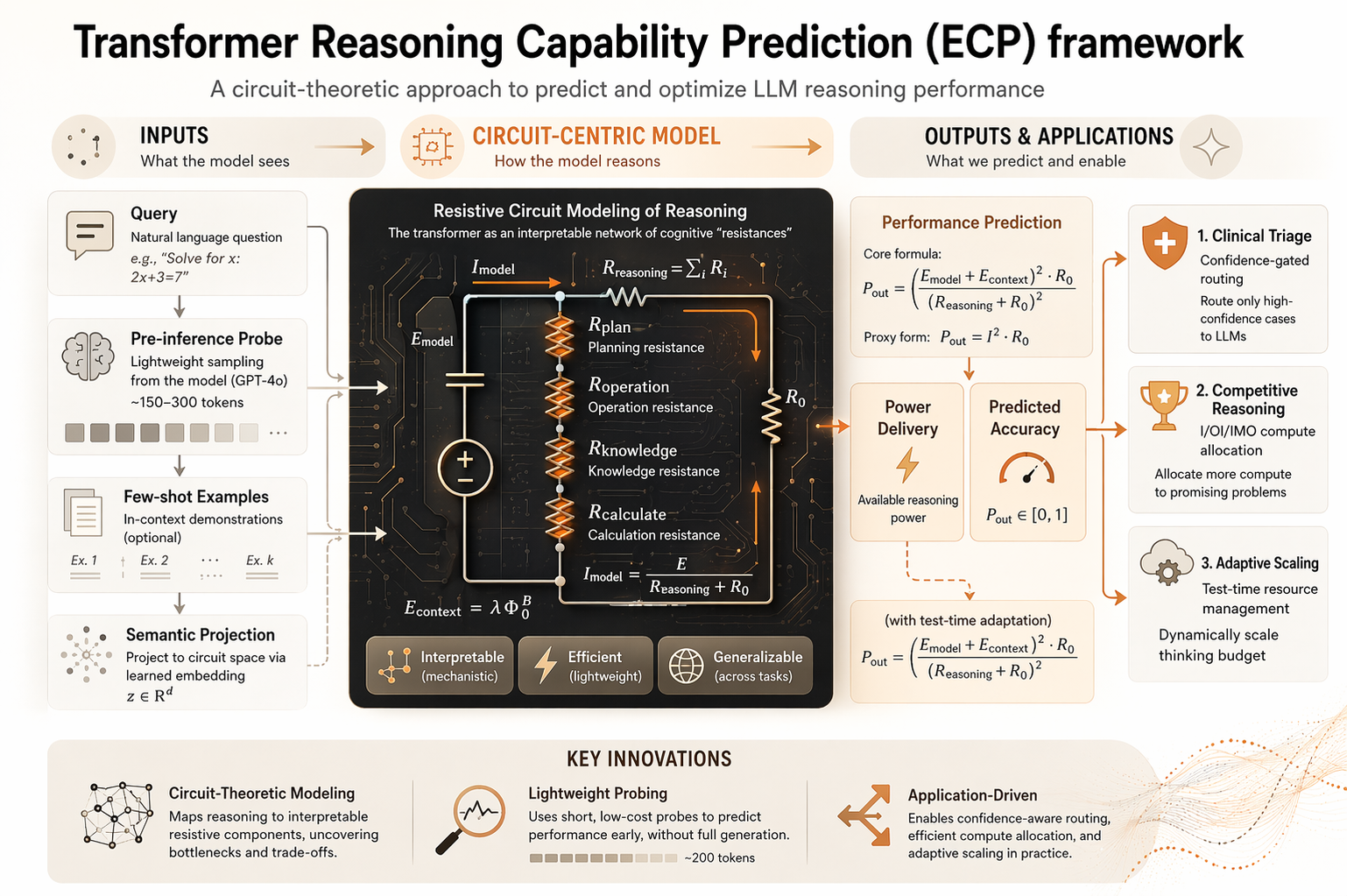
目录
- 摘要
- 目录
- 研究动机
- 电路定律的直觉
- 电路定律:形式化
- 为什么是这种函数形式?唯一性定理
- 我们是如何走到这一步的:发现历程
- 实验验证
- 以电路操作指导更好的上下文建模
- 以电路操作指导更好的推理策略
- 为什么更简单的替代方案不行?
- 应用
- 快速开始
- 当前支持的模型
- 讨论
研究动机
当你向LLM提出一个困难的推理问题时,你怎么知道——在它开始思考之前——它是否能答对?
如今,诚实的回答是:你不知道。 你运行模型,等待输出,然后检查。如果答错了,算力已经花掉了。如果是临床诊断或竞赛题目,你甚至可能在造成损失之后才发现答案是错的。
我们着手改变这一现状。我们想要一个轻量级的推理前信号,告诉你:"这个问题对这个模型在当前上下文下太难了——应该升级、检索更多证据,或分配更多算力。"
令人惊讶的发现是,这样的信号确实存在,而且它遵循一个精确的定量定律,来源出人意料:电子电路理论。
电路定律的直觉
一个变换器在解决多步推理问题时面临两种对立的力量:
- 上下文支撑,推动它走向答案(如同电压驱动电路)
- 推理复杂度,将它拉回(如同电阻耗散能量)
两者之间的平衡——而非单独任何一方——决定了成功与否。而这种平衡遵循的正是电路中有用功输出所遵循的功率传递方程。
这不是一个松散的比喻。我们证明了它是与自回归变换器四种结构性质一致的唯一函数形式。
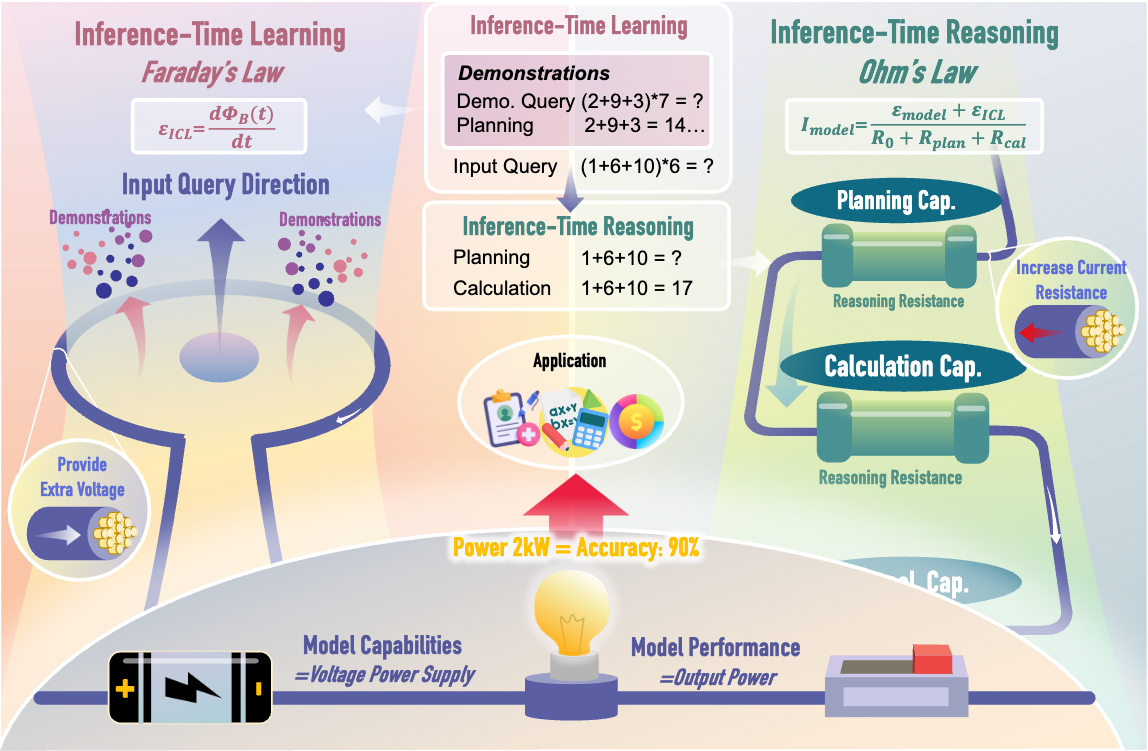 图1:推理前预测准确性(R² ≥ 0.95)在域内和分布外设置中均表现稳健。
图1:推理前预测准确性(R² ≥ 0.95)在域内和分布外设置中均表现稳健。
电路定律:形式化
模型的成功概率由以下公式决定:
$$P_{\text{out}} = \frac{(\mathcal{E}{\text{model}} + \mathcal{E}{\text{Context}})^2 \cdot R_0}{(R_{\text{Reasoning}} + R_0)^2} = I_{\text{model}}^2 \cdot R_0$$
关键组成部分:
| 符号 | 电路类比 | 含义 | 获取方式 |
|---|---|---|---|
| $\mathcal{E}_{\text{model}}$ | 电池电动势 | 模型固有能力 | 每个模型拟合一个标量 |
| $\mathcal{E}_{\text{Context}}$ | 辅助电动势 | 上下文驱动增益 = $\lambda\Phi_0^B$ | 示例的嵌入投影 |
| $R_{\text{Reasoning}}$ | 串联电阻 | 总推理负载 = $\sum R_i$ | 推理前探针(约150–300 token,<$0.002) |
| $R_0$ | 负载电阻 | 不可约解码瓶颈 | 拟合常数(跨任务共享) |
| $I_{\text{model}}$ | 电流 | 推理吞吐量 = $\frac{\mathcal{E}}{R_{\text{Reasoning}}+R_0}$ | 导出量 |
| $P_{\text{out}}$ | 输出功率 | 预测成功概率 | $I^2 \cdot R_0$ → 校准至 [0, 1] |
上下文驱动(推理时学习):
$$\mathcal{E}{\text{Context}} = \lambda \Phi_0^B, \quad \Phi_0^B = \sum{i=1}^{N} \frac{\vec{S}_q \cdot \vec{S}_i}{|\vec{S}_q|}$$
推理负载(推理时推理):
$$R_{\text{Reasoning}} = R_{\text{plan}} + R_{\text{operation}} + R_{\text{knowledge}} + R_{\text{calculate}}$$
每个分量仅从查询本身通过轻量级推理前探针(GPT-4o,约150–300 token)估计,独立于目标模型的生成过程。
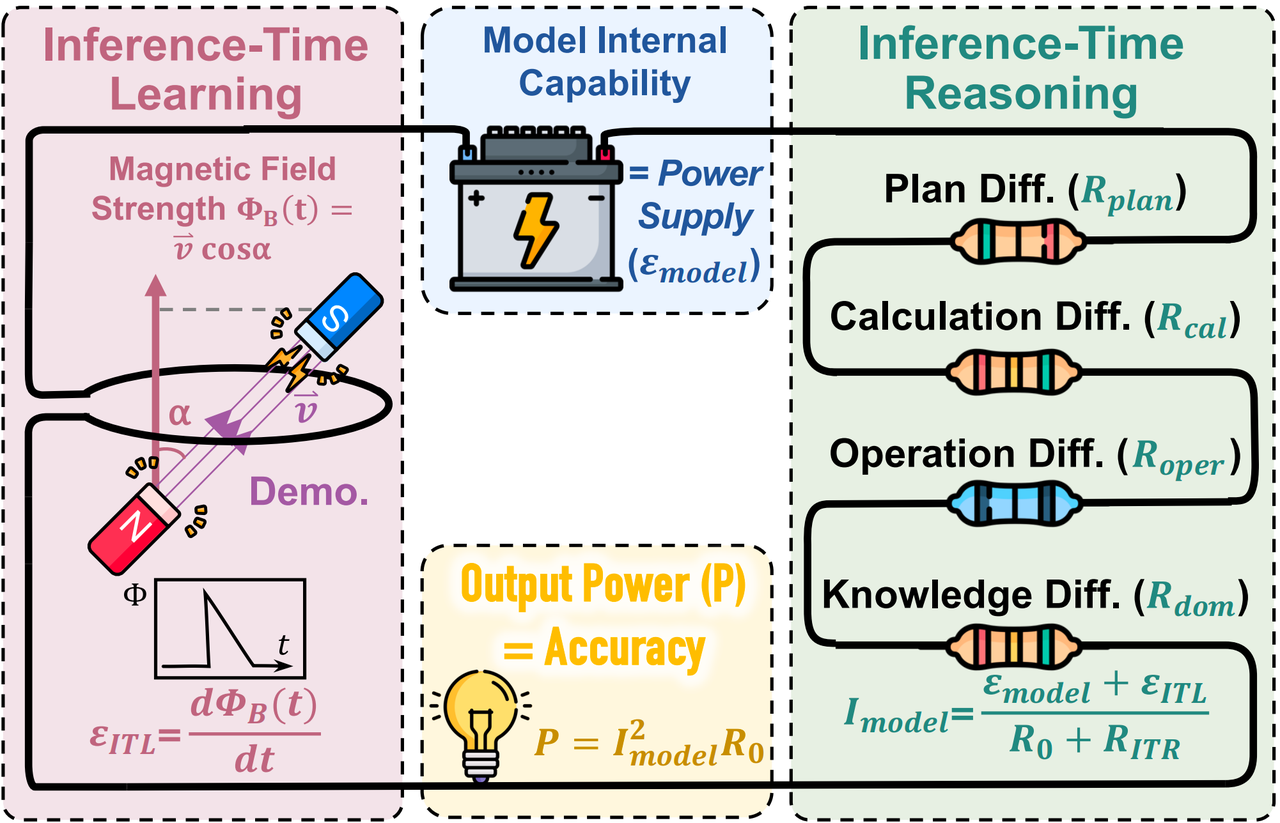 图2:LLM推理的电路类比。上下文支撑(电动势)和推理复杂度(电阻)决定输出功率(成功概率)。
图2:LLM推理的电路类比。上下文支撑(电动势)和推理复杂度(电阻)决定输出功率(成功概率)。
为什么是这种函数形式?唯一性定理
一个自然的问题:为什么偏偏是这种特定形式?更简单的模型能否同样有效?
我们证明了电路定律是与任何自回归变换器必须满足的四种结构性质一致的唯一函数形式:
-
负载可加性: 组合两个独立推理步骤会使难度线性增加:$R_{A \oplus B} = R_A + R_B$。这源于逐token生成——每一步都会累积误差。
-
单调递减收益: 增加上下文支撑总是有帮助的,但边际收益递减。形式化表述:当超过阻抗匹配点时,$\partial P / \partial \mathcal{E} > 0$ 且 $\partial^2 P / \partial \mathcal{E}^2 < 0$。这反映了少样本缩放曲线中的饱和现象。
-
阻抗匹配: 存在一个最优平衡点:当 $R_{\text{Reasoning}} = R_0$ 时,模型从上下文中提取最大"有用功"。低于此点,任务太简单,更多上下文无益;高于此点,无论提供多少上下文,任务都会压垮模型。
-
有界输出: 成功概率必须在 $[0, 1]$ 范围内,且随难度增加平缓退化(而非灾难性崩溃)。
定理(唯一性)。 任何满足性质1–4的连续函数 $P(\mathcal{E}, R)$ 必须具有以下形式:
$$P = \frac{\mathcal{E}^2 \cdot R_0}{(R + R_0)^2}$$
至多差一个输出的单调重缩放。换言之,电路定律是唯一可接受的预测器——不是从模型库中选出的,而是从第一性原理推导出的。
这有一个实际意义:无需在函数形式或神经网络架构上进行搜索。变换器的物理机制决定了预测方程。
我们是如何走到这一步的:发现历程
最初,我们尝试了标准方法来预测LLM推理的成功:
- 逻辑回归,基于手工设计的难度特征
- 神经校准器,在模型输出上进行事后训练
- 自我评估——让LLM对自身的置信度进行评分
没有一种方法达到令人满意的准确性(R² < 0.7),也无法迁移到未见过的任务。
突破来得出人意料。当我们将准确率曲线相对于推理深度绘图时,它们酷似电气工程中的功率耗散曲线。这一洞察引导我们将推理过程建模为电路,并从第一性原理推导出唯一的函数形式。
结果:域内R² ≥ 0.95,且在未见过的任务和模型上稳健迁移。
实验验证
规模: 70,000+实例 · 350+任务 · 9个LLM · 每个设置8次随机划分
模型: GPT-4o、GPT-4o-mini、GPT-3.5-Turbo、DeepSeek-R1 / V3、Gemini-2.0 / 1.5-Flash、Qwen2.5-7B / 32B、Qwen3-32B
基准测试: BBH(27个任务)· MMLU(57)· MMLU-Pro(14)· MATH(7)· GSM8K / BigGSM / BigGSM++ · GPQA / SuperGPQA(300+)· MedQA / PubMedQA / MedMCQA · HotpotQA · MGSM(11种语言)
推理前预测准确性
| 设置 | MSE | MAE | R² |
|---|---|---|---|
| 域内 | 0.0005 | 0.0174 | 0.9553 |
| 分布外-任务(留出任务) | 0.0031 | 0.0482 | 0.9087 |
| 分布外-模型(留出LLM) | 0.0033 | 0.0507 | 0.8493 |
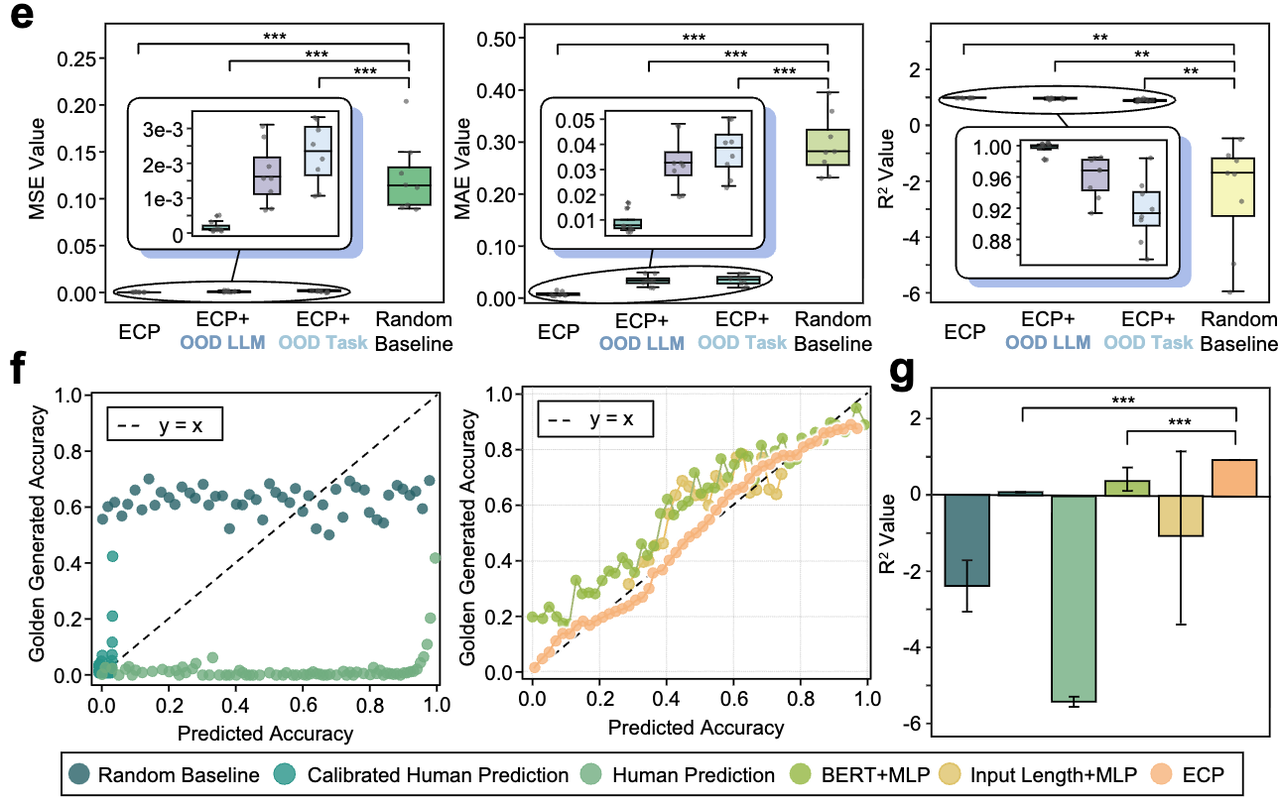 图3:电路定律预测(R² ≥ 0.95)稳健地泛化到留出的任务和模型。
图3:电路定律预测(R² ≥ 0.95)稳健地泛化到留出的任务和模型。
电路可组合性
电路定律产生两个可证伪的结构性预测——均已得到验证:
串联组合: 随着推理长度增长,$R_{\text{Reasoning}}$ 线性累积,准确率按 $(R_{\text{Reasoning}} + R_0)^{-2}$ 衰减。经验拟合:R² > 0.95。这解释了为什么极长的推理链会退化——信号在完成之前就已衰减。
并联组合(自一致性): 运行 $n$ 条并发推理链将有效电阻降低至 $R/n$。然而,样本间相关性限制了收益:有效独立轨迹按 $\log n$ 而非 $n$ 缩放。这为广泛观察到的推理时缩放收益递减提供了第一性原理解释,并给出了实例级别的最优采样预算停止规则。
 图4:串联和并联电路组合解释了推理长度退化和自一致性缩放极限。
图4:串联和并联电路组合解释了推理长度退化和自一致性缩放极限。
以电路操作指导更好的上下文建模
上下文只有在与查询有意义地对齐时才有帮助。与其将示例视为额外的提示内容,不如将它们视为可以支持或干扰推理的电路输入:
| 策略 | 电路操作 | 测量效果 |
|---|---|---|
| 零样本基线 | 移除示例 | ECP分数仍能追踪准确率 |
| 投影长度检索 | 选择对齐的支撑信号 | 与任务性能最佳一致 |
| 欧氏距离检索 | 标准几何相似度 | 不如投影长度 |
| BGE编码RAG | 改进语义支撑构建 | 理论-性能对齐更好 |
| 元识别编码RAG | 细粒度支撑表示 | 更高的理论功率和准确率 |
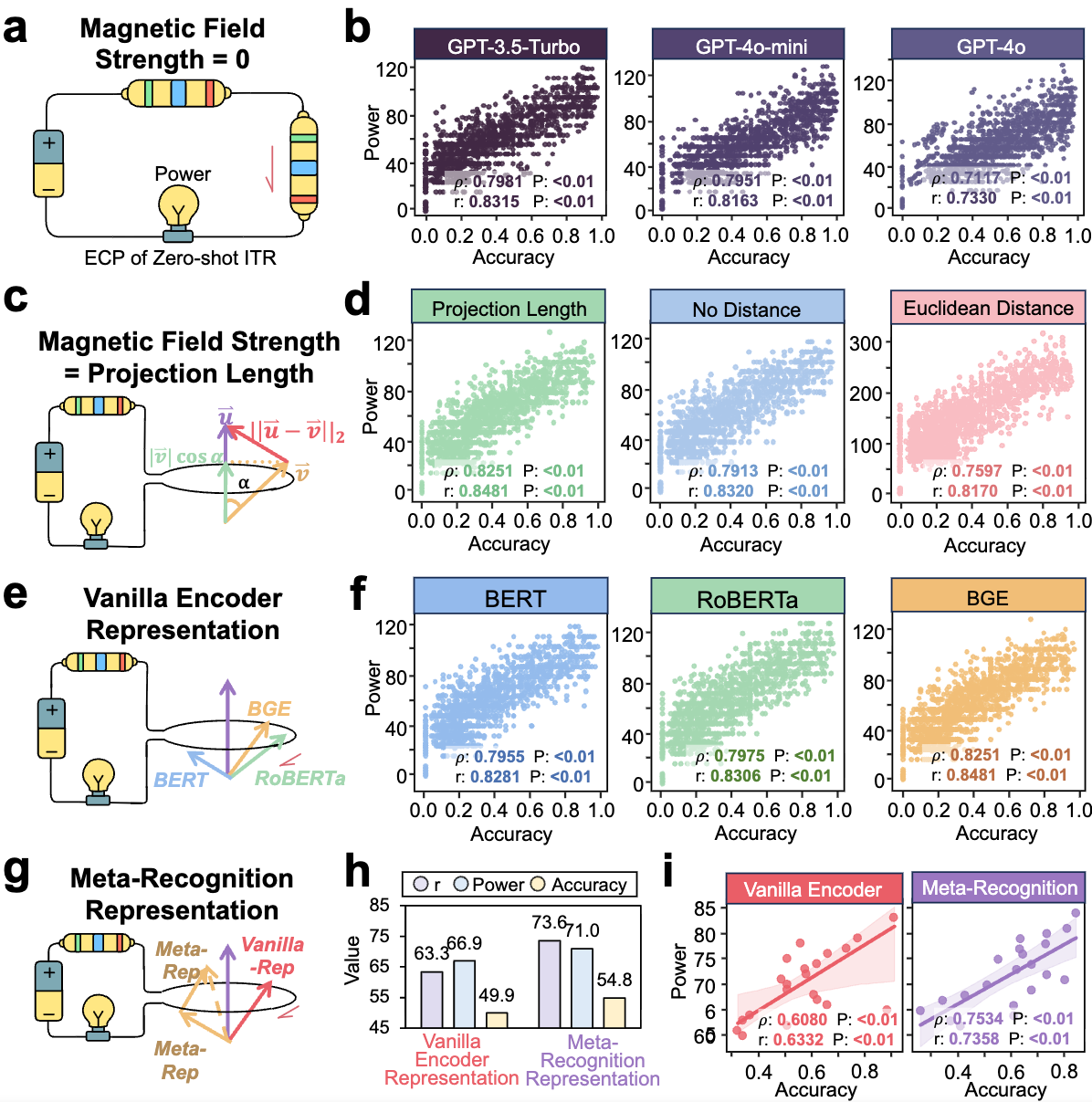 图5:投影长度检索最大化了上下文驱动与实际任务性能之间的对齐。
图5:投影长度检索最大化了上下文驱动与实际任务性能之间的对齐。
以电路操作指导更好的推理策略
每种主要的提示策略都映射到一个特定的电路操作,具有定量预测的效果:
| 策略 | 电路操作 | 测量效果 |
|---|---|---|
| 思维链(CoT) | 通过分解降低 $R_{\text{Reasoning}}$ | R: 4.40 → 3.97 ⬇️ 准确率: 33.6% → 41.7% ⬆️ |
| 少样本(top-k) | 通过语义对齐增加 $\mathcal{E}_{\text{Context}}$ | Spearman ρ = 0.83 与准确率相关 |
| 工具使用 | 将 $R_{\text{calculate}}$ 和 $R_{\text{operation}} \approx 0$(外部化) | r > 0.90,R² 提升 >10% |
| 程序化思维 | 降低规划和计算负载 | r > 0.95,R² > 0.89 |
| 测试时缩放 | 并联电阻:$R' = \frac{R}{n}$ | 有效样本的对数缩放已确认 |
| 上下文演化 | 迭代最大化 $\Phi_0^B$ | 比纯指令准确率提升 +20% |
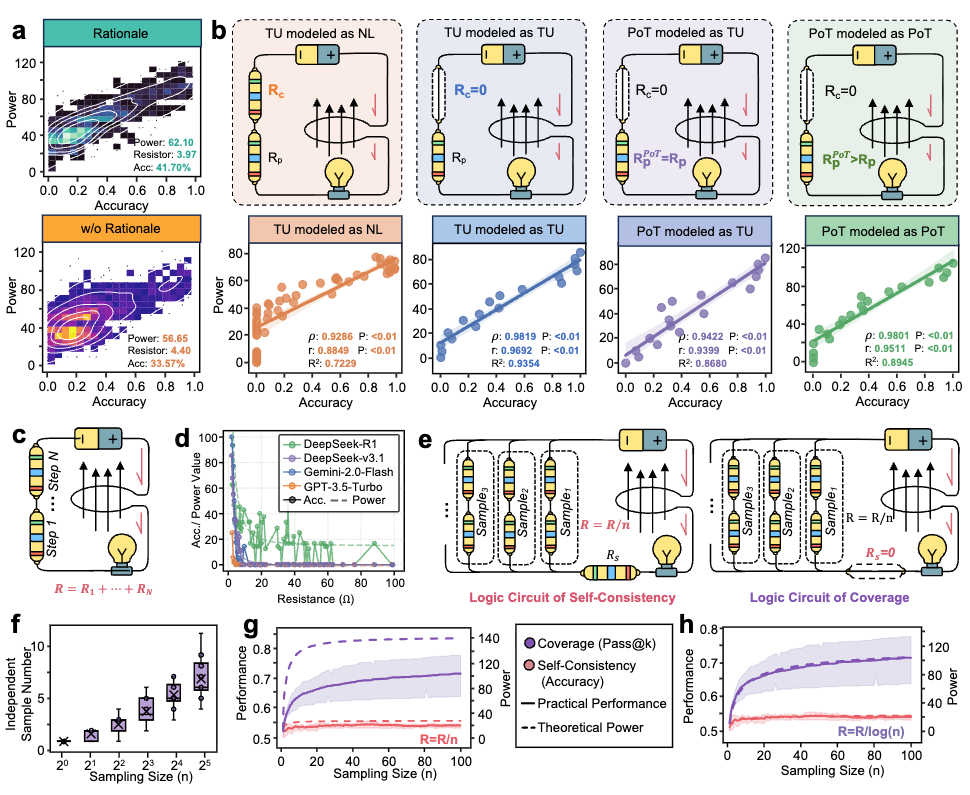
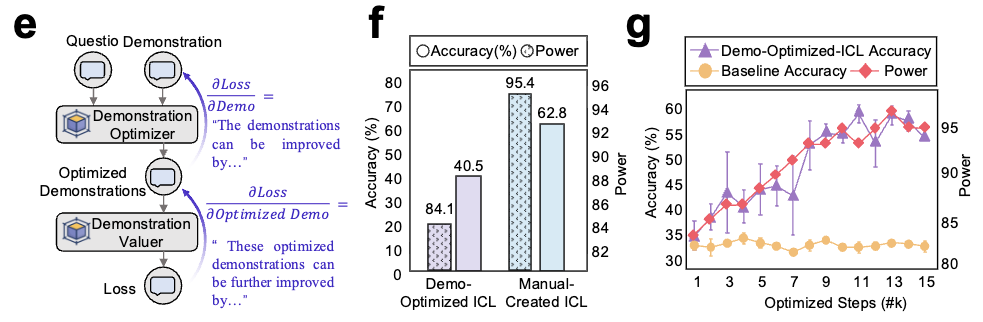 图6:提示技术通过降低推理负载或增加上下文驱动来提升性能,其效果可由电路定律定量预测。
图6:提示技术通过降低推理负载或增加上下文驱动来提升性能,其效果可由电路定律定量预测。
为什么更简单的替代方案不行?
读者自然会问:为什么不使用模型置信度、logprobs或学习型难度估计器?
| 替代方案 | 为什么不够好 |
|---|---|
| 模型自信度(logprobs) | 对推理任务校准不佳;R² < 0.45;无法迁移到新模型 |
| 特征线性回归 | 违反阻抗匹配;缺少交互项;R² < 0.65 |
| 神经校准器(事后) | 过拟合训练分布;在分布外任务上R²降至0.52 |
| 缩放定律 | 预测训练损失,而非逐实例推理成功率;是正交问题 |
| 输出长度启发式 | 弱相关(r < 0.53);仅事后可用;无推理前信号 |
电路定律不仅更好——它是与变换器结构一致的唯一形式。
应用
由于ECP产生可移植、校准良好的推理前难度信号,它可以作为真实系统的控制输入——路由算力、触发检索或升级到人工监督。
临床诊断:置信度门控分诊
我们在一个人机协作的医疗工作流中评估ECP作为决策层,涵盖三个基准测试(MedQA、PubMedQA、MedMCQA)的1,914个病例:
| 阶段 | 操作 | 触发条件 |
|---|---|---|
| 1. 推理前风险评估 | 从病史(上下文)和诊断推理步骤(负载)计算 $P_{\text{out}}$ | 所有病例 |
| 2. 自适应检索 | 检索临床指南并请求更强的LLM以提升 $\mathcal{E}_{\text{Context}}$;要求人工快速复核 | $0.3 \le P_{\text{out}} < 0.9$ |
| 3. 自动接受 | 高置信度预测自动接受 | $P_{\text{out}} \ge 0.9$ |
| 4. 升级 | 低置信度病例转交人类专家 | $P_{\text{out}} < 0.3$ |
结果: 在诊断准确率>98%的条件下,置信度门控策略相比完全人工审核降低总成本约30%,相比人类-Gemini基线降低约15%。校准指标:MSE = 0.0082,MAE = 0.0726,R² = 0.9291(GPT-4o)。
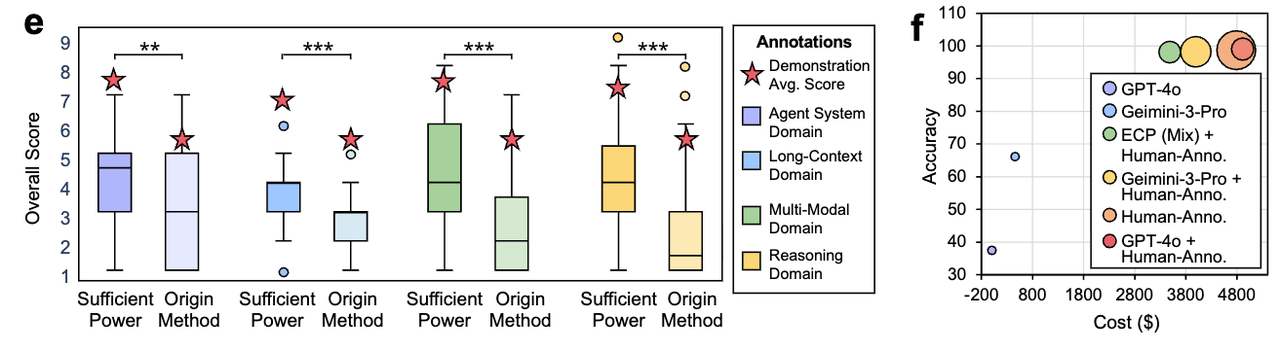
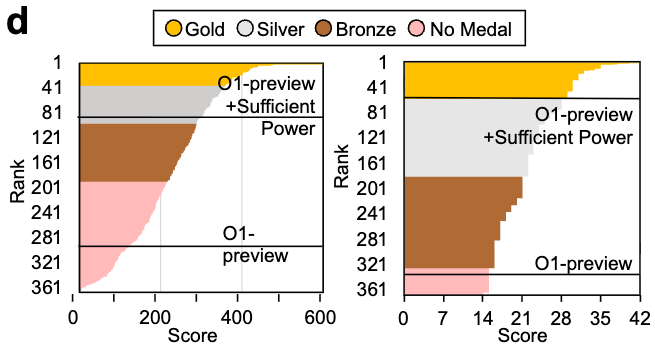 图7:ECP能够有效指导性能提升和成本降低,其中置信度门控分诊在保持>98%诊断准确率的同时降低30%成本。
图7:ECP能够有效指导性能提升和成本降低,其中置信度门控分诊在保持>98%诊断准确率的同时降低30%成本。
竞赛推理:IOI与IMO
使用负担引导的算力缩放(o1-preview)——识别每个实例的主导电阻瓶颈并在该处分配额外算力:
- IOI 2024:🥈 银牌——超越约80%的人类参赛者
- IMO 2024:🥉 铜牌——超越约80%的人类参赛者
- AI-Scientist:专家评定的新颖性和影响力分数提升超过1.0分
快速开始
安装
pip install fastapi uvicorn openai pyyaml pandas numpy
设置OpenAI API密钥用于GPT-4o探针:
export OPENAI_API_KEY="sk-..."
启动预测服务器
cd ecp && uvicorn api:app --reload --port 8000
交互式API文档位于 http://localhost:8000/docs
最小示例
import requests
resp = requests.post("http://localhost:8000/predict", json={
"model": "gpt-4o",
"query": "一个读书俱乐部有3对夫妇和5个单身人士,加上Ron和他的妻子。"
"成员每周轮流选书。"
"Ron一年能选几次书?"
})
result = resp.json()
print(result)
# {
# "predicted_accuracy": 0.52, ← 校准后的成功概率
# "U_icl": 0.023, ← 上下文驱动(ℰ_ITL)
# "R": 1.85, ← 总推理负载(R_ITR)
# "rubric": {"plan_num": 3, "calculate_num": 2, "operation_num": 1, "entity_num": 4}
# }
API端点
API支持渐进式预计算级别——提供更多输入可跳过上游调用并降低成本:
| 端点 | 描述 | 外部调用 | 成本 |
|---|---|---|---|
POST /predict | 完整流水线:评分标准提取 → 嵌入 → ECP | 1× Chat + 1× Embed | ~$0.0003 |
POST /predict/batch | 多实例批量预测 | 无 | - |
GET /models | 列出所有支持的模型及拟合参数 | — | — |
GET /tasks | 获取任务级别难度常数(400+任务) | — | — |
请求格式:
{
"model": "gpt-4o", // 必填:目标模型
"query": "问题文本...", // 必填:完整问题描述
"mode": "global" // 可选:"global"(默认)或 "per_model"
}
当前支持的模型
ECP有两种运行模式:全局模式(所有模型共享参数)和逐模型模式(模型专属拟合参数,精度更高)。
| 模型 | 全局模式 | 逐模型模式 |
|---|---|---|
| GPT-4o | ✅ | ✅ |
| GPT-4o-mini | ✅ | ✅ |
| GPT-3.5-Turbo | ✅ | ✅ |
| DeepSeek-R1-250120 | ✅ | ✅ |
| DeepSeek-V3.1 | ✅ | — |
| Gemini-2.0-Flash | ✅ | ✅ |
| Gemini-1.5-Flash / Pro | ✅ | ✅ |
| Qwen2.5-7B / 72B-Instruct | ✅ | — |
| Claude Sonnet 4 | ✅ | — |
扩展到新模型: 只需提供一个标量
U_model(固有能力值)即可在全局模式下运行任何新模型,无需重新训练。逐模型模式需要在小型校准集上拟合4个参数——详见论文。
讨论
为什么是电路理论?
电路定律不是通过曲线拟合得出的,而是从第一性原理推导而来。变换器本质上是顺序处理器:每个推理步骤都会累积出错的机会,正如串联电路中每个电阻都会累积电压降。功率传递方程自然地捕捉了驱动力(上下文)与累积负载(推理复杂度)之间的权衡。
这一洞察重新诠释了LLM缩放中一个长期存在的困惑:为什么少样本示例有帮助但收益递减?为什么更长的推理链会退化?为什么自一致性会趋于平台期?电路定律通过一个统一的框架回答了这三个问题。
对LLM设计的启示
- 上下文不是免费的。 电路定律精确量化了额外上下文何时不再有帮助,在阻抗匹配点 $R_{\text{Reasoning}} = R_0$。超过此点,无论提供多少证据,任务都会压垮模型。
- 推理分解是强大的。 思维链之所以有效,是因为它通过将复杂步骤分解为更简单的步骤来降低 $R_{\text{Reasoning}}$。电路定律可以预测这种收益的精确幅度。
- 模型缩放有极限。 增加 $\mathcal{E}_{\text{model}}$(通过更大的模型)有帮助,但收益以二次方递减。这解释了为什么缩放定律会趋于平台期,以及为什么推理专用模型(o1、R1)需要架构变革而非仅仅增大规模。
- 推理前预测使自适应系统成为可能。 我们首次可以在推理之前路由查询——将简单问题发送给小模型,困难问题发送给大模型或人类,而不会在注定失败的尝试上浪费算力。
更广泛的影响
ECP使推理感知的算力分配民主化。临床系统可以按预测难度分诊病例。教育平台可以实时调整题目难度。研究团队可以更高效地分配有限的GPU预算。医疗诊断中30%的成本降低仅仅是个开始。