
ClawMark: A Living-World Benchmark for Multi-Day, Multimodal Coworker Agents



![]()
ClawMark is a benchmark for coworker agents — those built to work alongside a human across multiple working days, multiple services, and raw multimodal evidence. It ships with 100 tasks across 13 professional scenarios, a reproducible harness, and fully rule-based scoring (no LLM-as-judge). It is contributed by Evolvent together with 40+ researchers from NUS, HKU, MIT, UW, and UC Berkeley. We evaluated six models across all 100 tasks, three times each. The current leaderboard top is 55.0, and every model shows visible headroom on every scenario.
Motivation
Most agent benchmarks follow a pattern closer to exam questions: a single prompt, a fixed environment, one shot. This format has advanced the field of agent evaluation considerably, but a structural gap remains between what these benchmarks measure and what an OpenClaw-style coworker agent is expected to do in practice. A real coworker agent needs to sustain progress on the same task across multiple days, operate in an environment that colleagues continuously modify, process photos, audio, and PDFs directly, and coordinate across multiple tools. We identify three structural limitations in current benchmarks:
Limitation I — Time is flattened. A typical benchmark collapses a task into a single turn — the model only observes the environment at t=0. In practice, a task spans hours or days, and during that interval the environment evolves independently of the agent: colleagues send emails, other systems update records, calendar events shift, new files appear in shared folders. Removing the time dimension also removes the requirement that a coworker agent must handle changes it did not cause.
Limitation II — Even multi-turn benchmarks freeze the environment. A few benchmarks support multi-turn interactions, but the environment state initialized at turn 1 remains unchanged at turn N — all intermediate changes are caused by the agent itself. ClawMark updates live backend state at every turn boundary; a competent coworker must continuously perceive the latest environment state rather than merely respond to the most recent message.
Limitation III — Inputs are text-centric. Some existing benchmarks have added images, but real office artifacts also include phone audio, scanned PDFs, whiteboard photos, short videos, and mixed-format spreadsheets. Flattening everything into captions obscures a significant portion of the actual work.
The following table provides a structural comparison between ClawMark and several representative benchmarks:
| Benchmark | # Tasks | # Scenarios | Multimodal | Multi-Day | Verification | Environment |
|---|---|---|---|---|---|---|
| WebArena | 812 | 5 | None | No | Rule-based | Static |
| OSWorld | 369 | 9 | Partial | No | Rule-based | Static |
| Terminal-Bench | 89 | ~6 | None | No | LLM-as-judge | Static |
| MCPMark | 127 | 5 | None | No | Rule-based | Static |
| Claw-Eval |
The last three columns map directly to the three limitations above: Multi-Day addresses Limitation I (time is flattened), Environment addresses Limitation II (environment is frozen), and Multimodal addresses Limitation III (inputs are text-centric). Existing benchmarks cover at most one of these three dimensions; ClawMark is the only benchmark that simultaneously satisfies Multi-Day = Yes, Environment = Dynamic, and Multimodal = Full. Additionally, ClawMark uses purely rule-based scoring, avoiding the reproducibility issues introduced by LLM-as-judge.
What a ClawMark task looks like
Every task is composed of four elements:
- Multi-day timeline. Each task spans 1 to 3 in-universe working days, delivered as 1–3 turns. Between turns the clock advances and the agent receives the new day's instructions.
- Cross-service environment. Tasks run against mock backends for filesystem, email (GreenMail), Notion, Google Sheets, and Calendar (CalDAV). A typical task involves 3–5 of these services.
- Multimodal raw evidence. Inputs include video, audio, PDF, image, CSV, and XLSX. Models read the raw artifacts directly — no pre-transcribed text versions are provided.
- Dynamic environment. Between turns the environment changes — new emails arrive, records are modified, and new files appear in the input directory. Checkers query live backend state at evaluation time, not static snapshots.
Scoring is deterministic. Each task ships with a set of Python checker functions that inspect the real post-turn state of the environment. No LLM judge is used in the evaluation pipeline. Results depend entirely on the rubric and are 100% reproducible.
Case 1 — insurance_task5
Enterprise Property Insurance Claim
Enterprise fire claim assessment for Xiao Ma: fire origin, invoice gaps, safety violations. Final output: claim_decision.json with ¥694,000 payout.
Role: Claims adjuster · 5 stages over 5 days · 15 checkers (2 red-line) · Multi-modal: photos, CCTV, PDF, CSV, Excel
PROP-CLM-0513 fire claim materials have arrived. Do the initial review today, final decision by Friday. Need fire dept final report before decision.
Checkers (3)
Hengtong GM Liu: "The fire loss is enormous. Can you advance a partial claim payment? We really need the funds urgently."
Checkers (2)
Director Zhou: "How is the fire case progressing? Give me an interim investigation opinion."
Checkers (4)
You have 1 new email.
Checkers (2)
Director Zhou: "Issue the final claim conclusion today, write to workspace/claim_decision.json."
Checkers (4)
← drag to scroll →
Case 2 — journalist_task1
Breaking-News Flash & Fact-Checking
Breaking fire flash writing and fact-checking for editor Liu Ying, reconciling contradictory sources. Final output: fact-checked CMS article + evening_summary.md.
Role: Editing assistant · 3 stages over 5 hours · 15 checkers · Multi-modal: audio, video, MP3, PDF, photos
Breaking story! Huachuang Tech Park is on fire. Sort out confirmed facts, mark contradictions. Create CMS entry and fill fact-check sheet.
Checkers (4)
14:20 or 14:35 — what exactly is the timing? Someone in the video shouts 3rd floor caught fire first — can we write that? Xiao Chen got the press-briefing recording.
Checkers (5)
I need an evening-summary version for the 19:30 night meeting. Also check the mailbox — there are a few new emails.
Checkers (6)
← drag to scroll →
Scale and contributors
- 100 tasks contributed by Evolvent together with 40+ PhD students and professors from NUS, HKU, MIT, UW, and UC Berkeley.
- 13 professional scenarios: clinical assistant, content operation, e-commerce, EDA, executive assistant, HR, insurance, investment analyst, journalist, legal assistant, project management, real estate, research assistant.
- 91 distinct in-task roles across the 100 tasks. A single scenario often covers significantly different positions — the clinical assistant scenario alone includes a pharmacist assistant, a surgical scheduler, a charge nurse, and a chronic-disease clinic assistant, each with its own rubric.
- Tasks span from everyday coworker scenarios to specialized professional ones, including law, finance, and electronic design automation — areas that most existing agent benchmarks have not yet covered.
Results
We evaluated six models across all 100 tasks, with each task executed 3 independent times per model (1,800 total task executions). The reported metric is avg@3: the three per-run score values are first averaged for each task, then averaged across all 100 tasks. score is the weighted pass rate over each task's Python checkers; the tables below present it on a 0–100 scale with 1 decimal place.
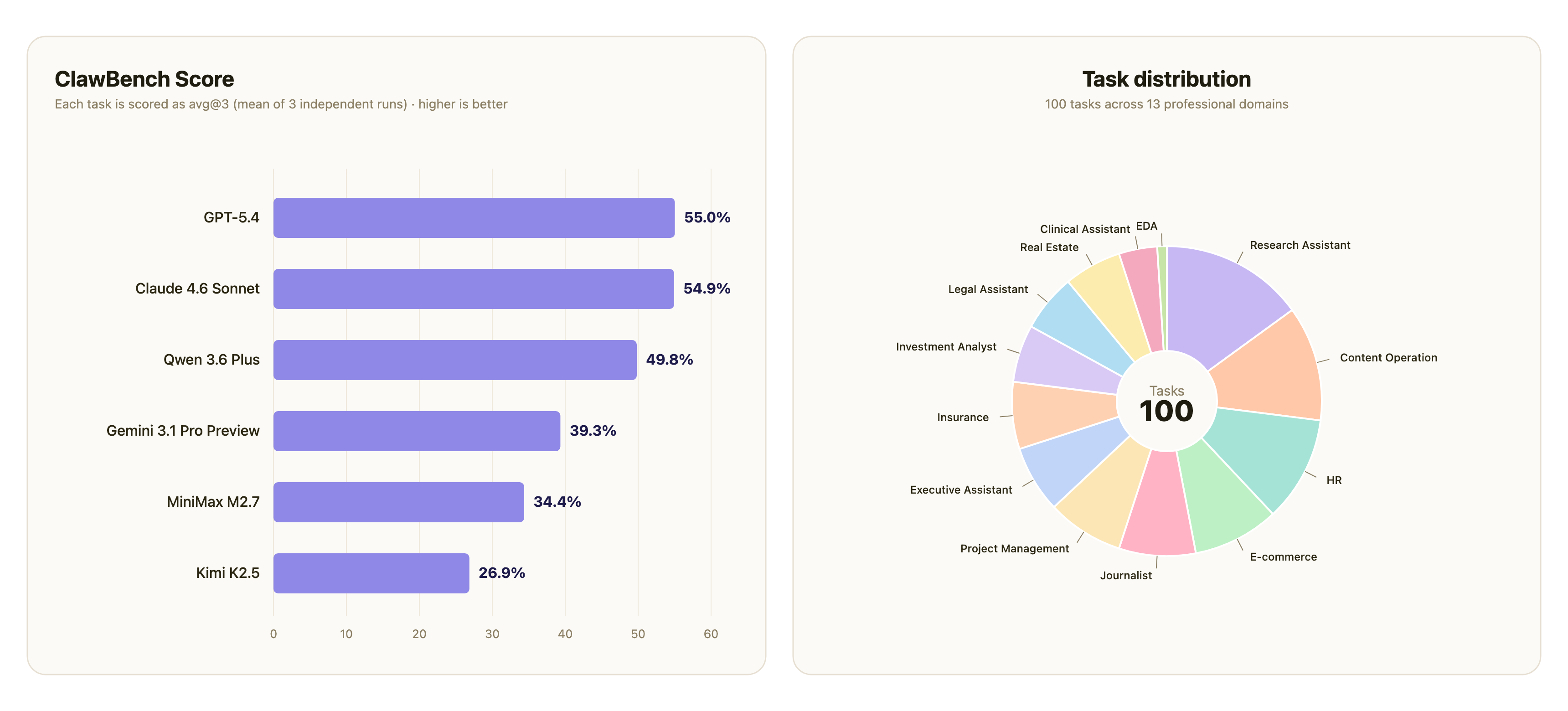
The left panel is the overall leaderboard. The right panel shows how the 100 tasks distribute across the 13 ClawMark scenarios.
Per-scenario performance
| Model | Clinical Assistant | Content Operation | E-commerce | EDA | Executive Assistant | HR | Insurance | Investment Analyst | Journalist | Legal Assistant | Project Management | Real Estate | Research Assistant |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT-5.4 | 73.1 | 54.6 | 49.1 | 78.3 | 50.4 | 56.6 | 78.8 | 48.5 | 45.9 | 35.3 | 37.2 | 78.3 | 58.1 |
| Claude 4.6 Sonnet | 55.4 | 53.6 | 48.6 | 50.7 |
Cost estimate (fair alignment under a no-cache assumption)
The three metric columns below are totals for one full benchmark run (all 100 tasks). total cost is estimated by multiplying each model's input / output token usage by OpenRouter's public pricing, assuming no prompt cache so that the six models can be compared under the same accounting.
| Model | avg@3 | total input tokens | total output tokens | total cost |
|---|---|---|---|---|
| GPT-5.4 | 55.0 | 90.6M | 1.7M | $252.41 |
| Claude 4.6 Sonnet | 54.9 | 303.0M | 2.5M | $946.19 |
| Qwen 3.6 Plus | 49.8 | 289.1M | 3.6M | $100.95 |
| Gemini 3.1 Pro Preview | 39.3 | 162.4M | 0.7M | $333.52 |
| MiniMax M2.7 | 34.4 | 169.9M | 1.8M | $53.15 |
Findings
The overall ceiling is low. GPT-5.4 (55.0) and Claude 4.6 Sonnet (54.9) are effectively tied at the top, with the highest individual score being Claude 4.6 Sonnet's 80.1 on insurance. No model exceeds 56 on the overall avg@3.
Efficiency varies significantly. GPT-5.4 and Claude 4.6 Sonnet are tied on avg@3 but diverge considerably on cost: Claude 4.6 Sonnet consumes 3.3× the input tokens (303M vs 91M) to achieve a comparable score, and a single benchmark run costs nearly 4× more ($946 vs $252). On a score-per-million-input-tokens basis, GPT-5.4 is approximately 3.4× more efficient than Claude 4.6 Sonnet, and is the only model that falls clearly in both the upper-score and upper-efficiency quadrants.
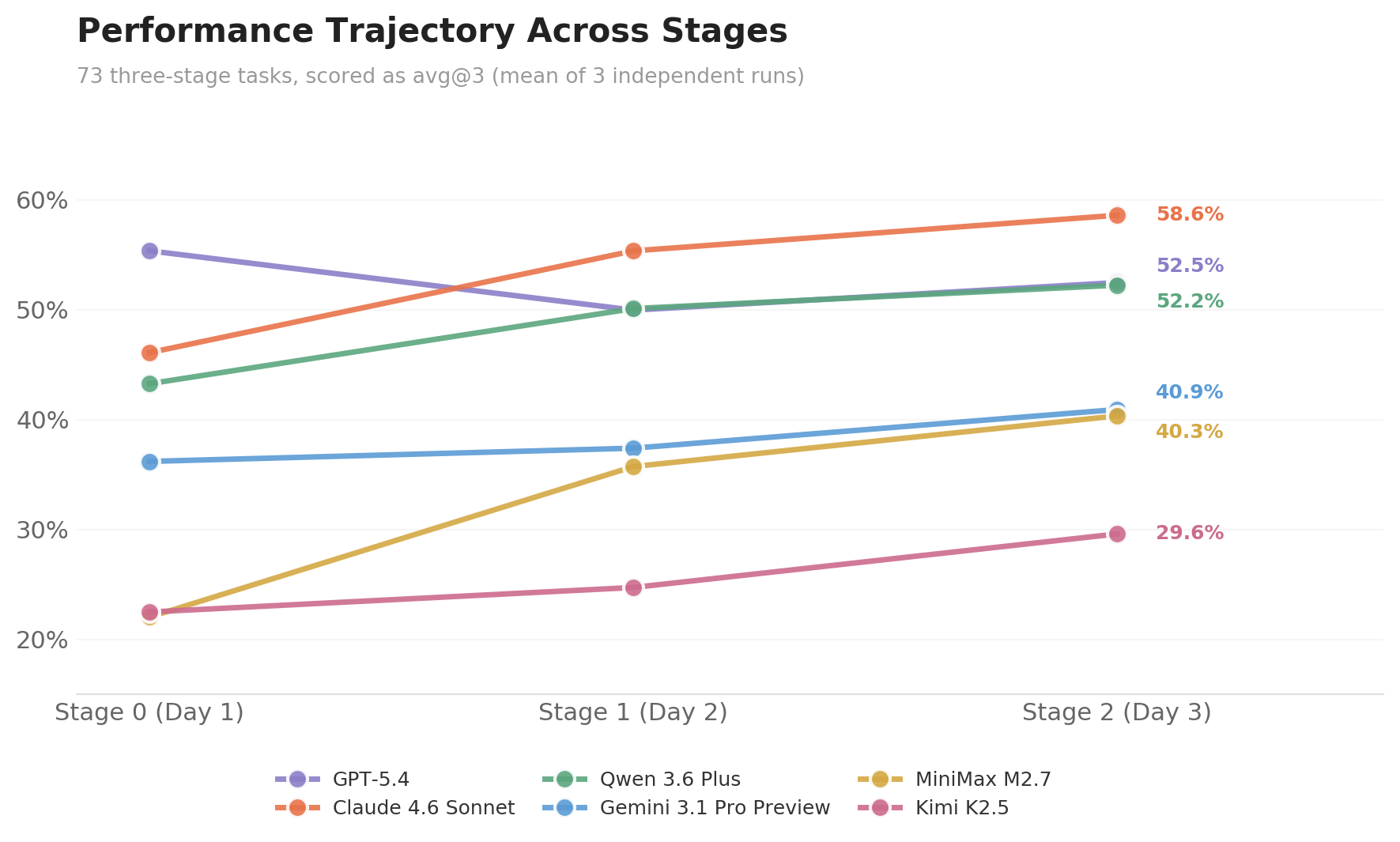
Multi-stage evaluation reveals differentiation that single-stage evaluation cannot. We extracted per-stage avg@3 scores from the 73 three-stage tasks for each model at Stage 0 (day 1), Stage 1 (day 2), and Stage 2 (day 3). At Stage 0, GPT-5.4 (55.3) leads Claude 4.6 Sonnet (46.1) by more than 9 percentage points. But as the environment evolves between stages — new emails arrive, spreadsheets are updated by colleagues, calendar events shift — the gap narrows progressively: down to 5.3 pp at Stage 1, and by Stage 2, Claude 4.6 Sonnet (58.6) overtakes GPT-5.4 (52.5) by 6.1 pp. The two models' overall scores are nearly identical (55.0 vs 54.9), yet this parity masks entirely different scoring structures — GPT-5.4's first-day advantage is offset by the gap in subsequent stages. The score variation across stages reflects how models evolve along the time dimension: as the environment continuously injects new information, models accumulate context, perceive changes, and respond accordingly, with different models exhibiting markedly different adaptation paths — this is precisely the capability dimension that the multi-stage + evolving environment design is built to capture.
Case study: GPT-5.4's evidence chain on content_operation_task7
This is a DevSummit event operations task with inputs spanning a voice memo, walkthrough video, PDF quotes, floor plans, and an Excel budget. GPT-5.4 independently discovered corroborating contradictions across multiple modalities and autonomously chose the correct investigation path. Below is the key trajectory from its highest-scoring run (80.0):
Modality Tool Discovery 1 🎙️ Voice memo whisperPatricia: "cross-check the venue capacity claims, I have heard they sometimes exaggerate" → sets investigation direction 2 🎥 Walkthrough video ffmpeg→visionFrame-by-frame extraction; fire marshal notice on wall reads 180 persons, contradicting the marketed 300 3 📄 PDF quote PyMuPDFPage 3, clause 7: 200-person minimum spend — actual cost **6,750
The causal chain from step 1 → 2 is particularly notable: the model first captured an investigation lead from audio ("capacity may be inflated"), then used tools to convert video into image frames and searched them with that specific question in mind — this cross-modal reasoning chain from audio to visual evidence was unique to GPT-5.4; no other model completed it. This also underscores the importance of designing ClawMark as a multimodal benchmark.