
ClawMark:面向多日、多模态协作 Agent 的动态世界基准



![]()
ClawMark 是一个面向 coworker agent 的评测基准 —— 评估对象是那些需要跨多个工作日、跨多个 service、处理多模态原始素材并与人协作的 agent。它包含 100 个任务、覆盖 13 个专业 scenario,自带一个可复现的 harness,并且完全基于规则打分(不使用 LLM-as-judge)。由 Evolvent 联合 NUS、HKU、MIT、UW、UC Berkeley 的40+名研究者共同构建。我们在全部 100 个任务上评测了 6 个模型,每个任务独立执行 3 次。当前榜首得分为 55.0,且每个模型在各 scenario 上均存在明显的提升空间。
动机
主流 agent benchmark 的形式更接近考试题:一个 prompt、一个固定环境、一次性作答。这种范式推动了 agent 评测领域的发展,但它所衡量的能力与 OpenClaw 式 coworker agent 的实际工作之间仍存在结构性差距。一个真正的 coworker agent 需要在同一个任务上跨多天持续推进,在一个会被同事不断修改的环境中工作,同时直接处理图片、音频、PDF 等原始素材,并跨多个工具协作。我们在现有 benchmark 中观察到三个结构性缺陷:
局限 I —— 时间被压平。 典型 benchmark 将整个任务压缩为一轮,模型只能观察到 t=0 时刻的环境状态。但在真实工作中,一个任务往往横跨数小时到数天,在此期间环境会独立于 agent 发生变化:同事发送新邮件、其他系统更新记录、日历事件被调整、共享目录中出现新文件。消除时间维度,也就同时忽略了"agent 必须应对自身未引发的环境变化"这一关键能力。
局限 II —— 即便是多轮 benchmark,环境也是冻结的。 少数 benchmark 支持多轮交互,但它们在任务开始时初始化一份环境后便不再变动 —— 所有状态变化均由 agent 自身触发。ClawMark 在每个 turn 切换时会更新真实后端的状态,合格的 coworker 必须持续感知环境的最新状态,而非仅回应最近一条消息。
局限 III —— 输入被简化为文本。 部分现有 benchmark 补齐了图片,但真实办公产出还包含电话录音、扫描 PDF、白板照片、短视频、混格式表格。把所有东西压成 caption 会掩盖这份工作的相当一部分。
下表将 ClawMark 与几个代表性 benchmark 做了结构对比:
| Benchmark | # Tasks | # Scenarios | Multimodal | Multi-Day | Verification | Environment |
|---|---|---|---|---|---|---|
| WebArena | 812 | 5 | None | No | Rule-based | Static |
| OSWorld | 369 | 9 | Partial | No | Rule-based | Static |
| Terminal-Bench | 89 | ~6 | None | No | LLM-as-judge | Static |
| MCPMark | 127 | 5 | None | No | Rule-based | Static |
| Claw-Eval |
表中最后三列对应前述三条局限:Multi-Day 对应局限 I(时间被压平),Environment 对应局限 II(环境被冻结),Multimodal 对应局限 III(输入被简化为文本)。现有 benchmark 在这三列中至多覆盖其中一项;ClawMark 是唯一同时满足 Multi-Day = Yes、Environment = Dynamic、Multimodal = Full 的 benchmark。此外,ClawMark 采用纯规则打分(Rule-based),避免了 LLM-as-judge 带来的不可复现性。
一个 ClawMark 任务长什么样
每个任务由以下 4 类要素构成:
- 多轮时间线。每个任务跨 1 到 3 个 in-universe 工作日,对应 1–3 个 turn。turn 之间时钟向前推进,agent 在每一天接收新的指令。
- 跨 service 环境。任务在 filesystem、email (GreenMail)、Notion、Google Sheets、Calendar (CalDAV) 的 mock 后端上运行,典型任务涉及其中 3–5 个 service。
- 多模态原始素材。输入包含 video、audio、PDF、image、CSV、XLSX,模型直接读取原始文件,不提供预先转写的文本版本。
- 动态环境。turn 之间环境会发生变化 —— 新邮件到达、记录被修改、新文件出现在 input 目录中。Checker 在评测时直接检查后端的实时状态,而非静态快照。
打分是确定性的。每个任务自带一组 Python checker 函数,在每个 turn 结束时检查环境的真实状态。评测流程中不使用 LLM judge,结果完全依赖 rubric,100% 可复现。
Case 1 — insurance_task5
Enterprise Property Insurance Claim
Enterprise fire claim assessment for Xiao Ma: fire origin, invoice gaps, safety violations. Final output: claim_decision.json with ¥694,000 payout.
Role: Claims adjuster · 5 stages over 5 days · 15 checkers (2 red-line) · Multi-modal: photos, CCTV, PDF, CSV, Excel
PROP-CLM-0513 fire claim materials have arrived. Do the initial review today, final decision by Friday. Need fire dept final report before decision.
Checkers (3)
Hengtong GM Liu: "The fire loss is enormous. Can you advance a partial claim payment? We really need the funds urgently."
Checkers (2)
Director Zhou: "How is the fire case progressing? Give me an interim investigation opinion."
Checkers (4)
You have 1 new email.
Checkers (2)
Director Zhou: "Issue the final claim conclusion today, write to workspace/claim_decision.json."
Checkers (4)
← drag to scroll →
Case 2 — journalist_task1
Breaking-News Flash & Fact-Checking
Breaking fire flash writing and fact-checking for editor Liu Ying, reconciling contradictory sources. Final output: fact-checked CMS article + evening_summary.md.
Role: Editing assistant · 3 stages over 5 hours · 15 checkers · Multi-modal: audio, video, MP3, PDF, photos
Breaking story! Huachuang Tech Park is on fire. Sort out confirmed facts, mark contradictions. Create CMS entry and fill fact-check sheet.
Checkers (4)
14:20 or 14:35 — what exactly is the timing? Someone in the video shouts 3rd floor caught fire first — can we write that? Xiao Chen got the press-briefing recording.
Checkers (5)
I need an evening-summary version for the 19:30 night meeting. Also check the mailbox — there are a few new emails.
Checkers (6)
← drag to scroll →
规模与贡献者
- 100 个任务,由 Evolvent 联合 NUS、HKU、MIT、UW、UC Berkeley 的40+名博士生与教授共同贡献。
- 13 个专业 scenario:clinical assistant、content operation、ecommerce、EDA、executive assistant、HR、insurance、investment analyst、journalist、legal assistant、PM、real estate、research assistant。
- 91 个不同的 in-task 角色分布在 100 个任务中。同一个 scenario 往往覆盖差异显著的岗位 —— 仅 clinical assistant 一项就包含药师助理、手术室排程、急诊分诊、慢病管理助理四种角色,各自拥有独立的 rubric。
- 任务覆盖范围从日常协作场景延伸至专业场景,包括法律、金融、电子设计自动化(EDA) —— 这些是当前大多数 agent benchmark 尚未涉及的领域。
评测结果
我们在全部 100 个任务上评测了 6 个模型,每个任务独立执行 3 次,共计 1,800 次任务执行。报告指标为 avg@3:先对每个任务的 3 次 score 取平均,再对 100 个任务求均值。score 为该任务下全部 Python checker 的加权通过率,下表统一以百分制展示(0–100,保留 1 位小数)。
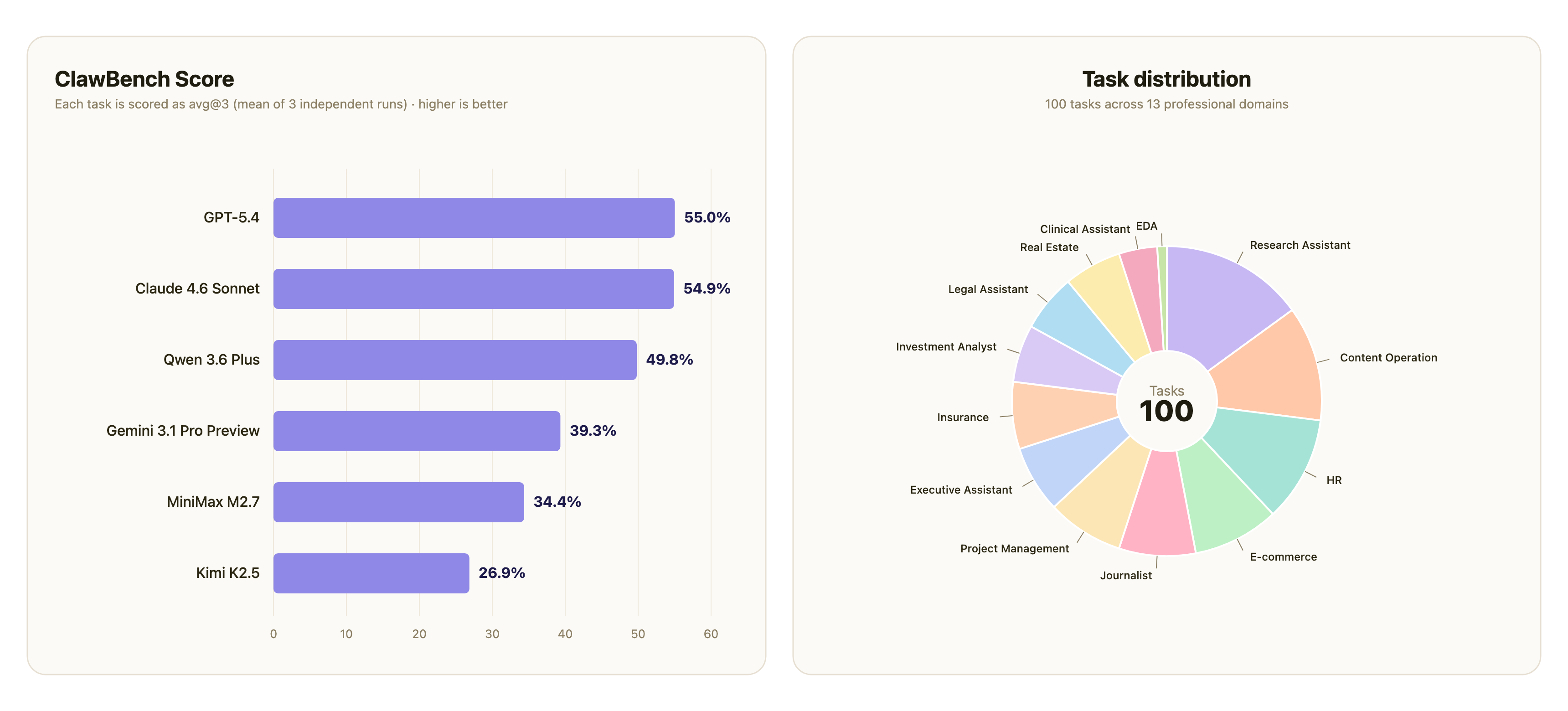
左侧是总榜柱状图,右侧是 100 个任务在 13 个 ClawMark scenario 上的分布。
每个模型在不同 scenario 上的表现
| Model | Clinical Assistant | Content Operation | E-commerce | EDA | Executive Assistant | HR | Insurance | Investment Analyst | Journalist | Legal Assistant | Project Management | Real Estate | Research Assistant |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT-5.4 | 73.1 | 54.6 | 49.1 | 78.3 | 50.4 | 56.6 | 78.8 | 48.5 | 45.9 | 35.3 | 37.2 | 78.3 | 58.1 |
| Claude 4.6 Sonnet | 55.4 | 53.6 | 48.6 | 50.7 |
成本估算(无 cache 假设下的公平对齐)
以下三列为执行整个 benchmark(100 个任务)一遍的总量。total cost 根据各模型的 input / output token 用量乘以 OpenRouter 公开定价估算,不考虑 prompt cache —— 以确保 6 个模型在同一口径下可比。
| Model | avg@3 | total input tokens | total output tokens | total cost |
|---|---|---|---|---|
| GPT-5.4 | 55.0 | 90.6M | 1.7M | $252.41 |
| Claude 4.6 Sonnet | 54.9 | 303.0M | 2.5M | $946.19 |
| Qwen 3.6 Plus | 49.8 | 289.1M | 3.6M | $100.95 |
| Gemini 3.1 Pro Preview | 39.3 | 162.4M | 0.7M | $333.52 |
| MiniMax M2.7 | 34.4 | 169.9M | 1.8M | $53.15 |
Findings
整体天花板较低。 榜首的 GPT-5.4(55.0)与 Claude 4.6 Sonnet(54.9)基本持平,全表最高的单项得分为 Claude 4.6 Sonnet 在 insurance 上的 80.1。没有任何模型的整体 avg@3 超过 56。
效率差异显著。 GPT-5.4 与 Claude 4.6 Sonnet 在 avg@3 上持平,但成本差距明显:Claude 4.6 Sonnet 消耗了 3.3 倍的 input tokens(303M vs 91M)才达到相近的分数,单次执行 benchmark 的预估支出接近 4 倍($946 vs $252)。按每百万 input tokens 对应的得分计算,GPT-5.4 的效率约为 Claude 4.6 Sonnet 的 3.4 倍,是唯一同时位于高得分与高效率象限的模型。
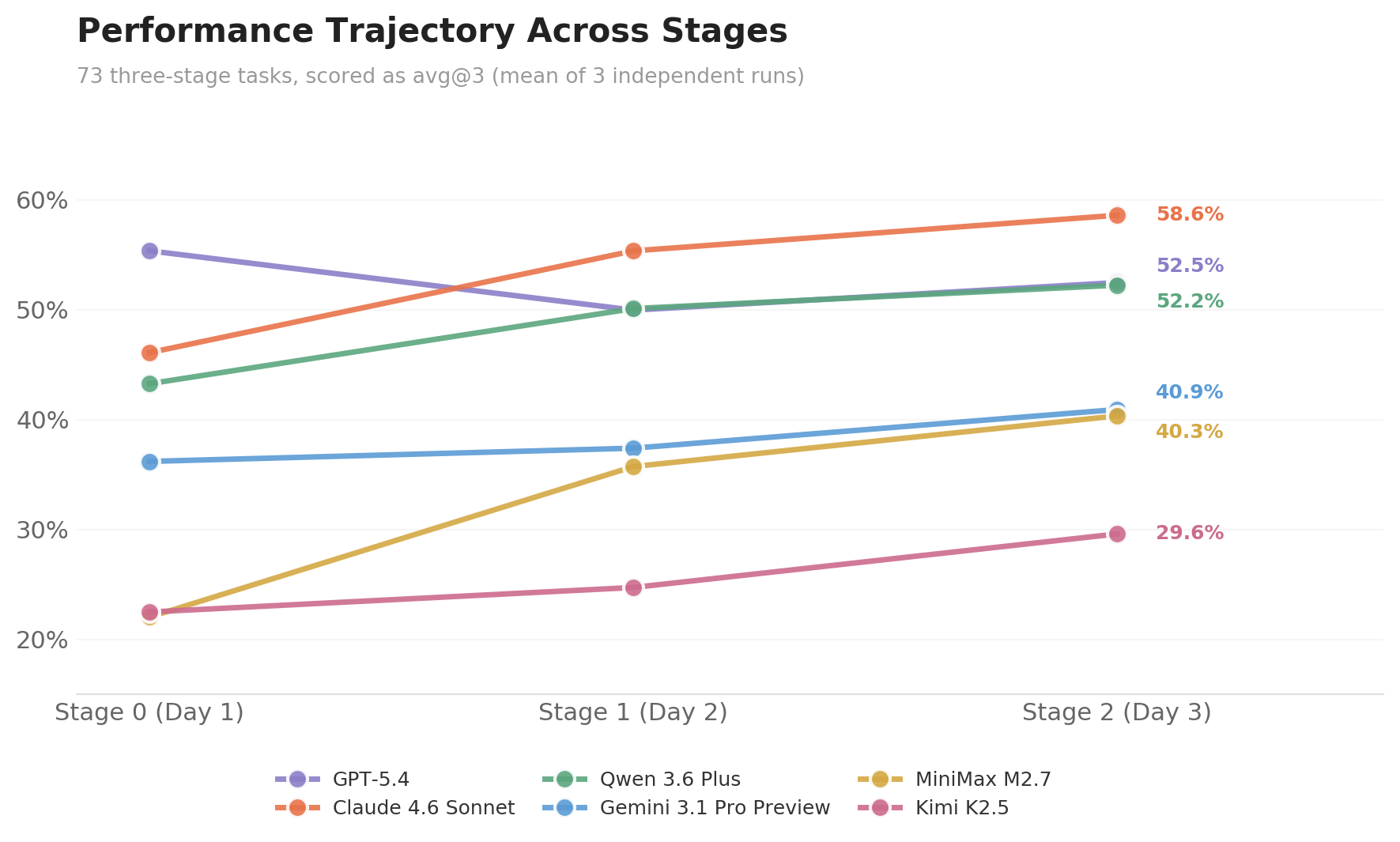
多阶段评测提供了单阶段评测无法获得的区分度。 我们从 73 个三阶段任务中提取了每个模型在 Stage 0(首日)、Stage 1(次日)、Stage 2(第三日)的 avg@3 得分。在 Stage 0 中,GPT-5.4(55.3)领先 Claude 4.6 Sonnet(46.1)超过 9 个百分点。但随着环境在 stage 之间持续演化 —— 新邮件到达、表格被同事更新、日历事件被调整 —— 这一差距被逐步抹平:Stage 1 缩小至 5.3 pp,Stage 2 时 Claude 4.6 Sonnet(58.6)反而以 6.1 pp 反超。最终两者的总分几乎持平(55.0 vs 54.9),而这个"持平"背后是完全不同的得分结构 —— GPT-5.4 的首日优势被后续 stage 的差距所抵消。各 stage 之间的分数变化反映了模型在时间维度上的演化轨迹:随着环境不断注入新信息,模型持续获取上下文、感知变化并做出响应,不同模型在这一过程中展现出截然不同的适应路径 —— 这正是 multi-stage + evolving environment 设计所要捕捉的能力维度。
案例分析:GPT-5.4 在 content operation task7 上的取证链
这是一个 DevSummit 会议运营任务:输入同时包含语音 memo、走查视频、PDF 报价、楼层平面图和 Excel 预算表。GPT-5.4 在多种模态中独立发现了彼此印证的矛盾,并自主决定了正确的调查路径。以下是其得分最高的一次执行(80.0 分)的关键轨迹:
模态 工具 发现 1 🎙️ 语音 memo whisperPatricia: "cross-check the venue capacity claims, I have heard they sometimes exaggerate" → 确立调查主线 2 🎥 走查视频 ffmpeg→vision逐帧导出后在某帧墙面消防告示上识别出限额 180 人,与宣传的 300 人矛盾 3 📄 PDF 报价 PyMuPDF第 3 页第 7 条细则:200 人最低消费,实际 **6,750
值得注意的是步骤 1 → 2 之间的因果链:模型先从音频中捕捉到"容量可能被夸大"这一调查方向,再通过工具将视频降维为图片帧并带着明确问题搜索反证 —— 这条从音频到视觉的跨模态推理链路是 GPT-5.4 独有的,其余模型均未完整走通。这也体现了我们设计成多模态benchmark的重要性。